It looks like you're using an Ad Blocker.
Please white-list or disable AboveTopSecret.com in your ad-blocking tool.
Thank you.
Some features of ATS will be disabled while you continue to use an ad-blocker.

How does Evolution explain Male and Female - Why are there two sexes Creating Genetic Variations ?
page: 23share:
a reply to: cooperton
Computer/software code is nothing like DNA for the following reasons:
1. The computer itself and the software that runs on it required the inspiration and development of humans. A computer and the software are not self replicating and can never be self replicating without human input.
2. DNA is self replicating. That implies that it was always self replicating. The first self assembled DNA molecule was by default self replicating. It needed no outside input to design or for future development.
3. DNA can actively correct errors, change its constituent code, evolve by mutation or novel processes. It is self sustaining. RNA and enzymes which interface with the DNA molecule are part of the complex system.
4. DNA is a dynamical system which is never in thermal equilibrium. No outside force is required to boot it up or shut it down.
5. DNA is an informational molecule. Its bioenergetics are provided by the energy flow through the system beginning with the sun. Therefore, other than a suitable environment for energy flow, nothing else is required for a self replicating molecule like DNA to exist.
6. You can lay out all the internal components of a computer on a table including the script for a program like C++. You can wait a thousand years and it will never assemble itself. The examples of self assembly of nucleic acids, micelles and amino acids are well known phenomena reproduced in countless laboratories.
Your description of DNA as just a “code” trivializes the complexity of a molecule that actually has very little in common with a computer or software other than information storage. One requires direct input from an external force like a human. The other requires nothing but a suitable chemical environment to assemble a naturally occurring self replicating molecule.
Computer/software code is nothing like DNA for the following reasons:
1. The computer itself and the software that runs on it required the inspiration and development of humans. A computer and the software are not self replicating and can never be self replicating without human input.
2. DNA is self replicating. That implies that it was always self replicating. The first self assembled DNA molecule was by default self replicating. It needed no outside input to design or for future development.
3. DNA can actively correct errors, change its constituent code, evolve by mutation or novel processes. It is self sustaining. RNA and enzymes which interface with the DNA molecule are part of the complex system.
4. DNA is a dynamical system which is never in thermal equilibrium. No outside force is required to boot it up or shut it down.
5. DNA is an informational molecule. Its bioenergetics are provided by the energy flow through the system beginning with the sun. Therefore, other than a suitable environment for energy flow, nothing else is required for a self replicating molecule like DNA to exist.
6. You can lay out all the internal components of a computer on a table including the script for a program like C++. You can wait a thousand years and it will never assemble itself. The examples of self assembly of nucleic acids, micelles and amino acids are well known phenomena reproduced in countless laboratories.
Your description of DNA as just a “code” trivializes the complexity of a molecule that actually has very little in common with a computer or software other than information storage. One requires direct input from an external force like a human. The other requires nothing but a suitable chemical environment to assemble a naturally occurring self replicating molecule.
edit on 21-1-2019 by Phantom423 because: (no reason given)
edit on 21-1-2019 by Phantom423 because: (no reason given)
originally posted by: Phantom423
a reply to: cooperton
Computer/software code is nothing like DNA for the following reasons:
1. The computer itself and the software that runs on it required the inspiration and development of humans. A computer and the software are not self replicating and can never be self replicating without human input.
Yes, computer code requires the development of humans. Just like genetic code requires the development by a Creator.
2. DNA is self replicating. That implies that it was always self replicating. The first self assembled DNA molecule was by default self replicating. It needed no outside input to design or for future development.
Yes, a process that we humans have been incapable of programming into computers. This shows that the design of humans and living organisms far surpasses the intelligent capabilities of humans. Another testament to the intelligence required to design life.
3. DNA can actively correct errors, change its constituent code, evolve by mutation or novel processes. It is self sustaining. RNA and enzymes which interface with the DNA molecule are part of the complex system.
This is what anti-virus programs do on computers.
4. DNA is a dynamical system which is never in thermal equilibrium. No outside force is required to boot it up or shut it down.
Computers can be programmed to turn on or off without user input. When a computer gets too hot, there is a program that triggers a fan to cool it down.
5. DNA is an informational molecule.
Computer code is information too.
6. You can lay out all the internal components of a computer on a table including the script for a program like C++. You can wait a thousand years and it will never assemble itself. The examples of self assembly of nucleic acids, micelles and amino acids are well known phenomena reproduced in countless laboratories.
Your description of DNA as just a “code” trivializes the complexity of a molecule that actually has very little in common with a computer or software other than information storage. One requires direct input from an external force like a human. The other requires nothing but a suitable chemical environment to assemble a naturally occurring self replicating molecule.
According to your theory code can self-assemble. But according to logic the genetic code could not have self-assembled into a coherent coding system. There are hundreds of proteins necessary for the first life. These proteins would have needed a meticulous precise coding to assimilate the proper amino acid sequence that would allow a viable cell. This insurmountable leap would be similar to a gorilla writing the entire code for the first apple computer from scratch.
edit on 21-1-2019 by cooperton because: (no reason given)
originally posted by: cooperton
Of course computer code is like genetic code. It is literally called genetic code. You are just trying to over-complicate things to avoid the obvious answer.
Equivocation fallacy.
Of course government law is like scientific law. It is literally called scientific law
There is nothing complicated about my explanation. Appealing to buzz words is not a valid argument and neither is equivocation. Go ahead and compare a programming language to the genetic code and show me some similarities. All you have is one common word, LMAO!
originally posted by: Barcs
. Go ahead and compare a programming language to the genetic code and show me some similarities.
Computer code is based on 1's and 0's. A binary yes or no option that serves as the basis for more complex coding. Similarly the genetic code has an A, G, T or C option for each of its positions in a coding sequence. These sequences code for a function called DNA polymerase, and other necessary programs, to come and parse the information and generate a functioning protein program that executes various functions throughout the organism. These processes have many fail-safes that prevent dangerous alterations from occurring, and it can even correct source-code errors on its own.
Epigenetics is a beautiful emerging field that shows the ability to amplify or diminish various parts of the source code (genetic code). It helps handle novel conditions or stimuli by either increasing or decreasing executive functions (protein expression). This process is seamless and requires no user input, because it is all integrated to a self-regulating fail-safe system that allows the biological computer to adapt to variable environments. This may seem like a deviation from computer code, but it is actually the epidome of what computer code wishes to accomplish - Artificial intelligence and advanced self-regulating mechanisms. This would be ideal for any computer software or hardware company that could offer the next level advancements in robotics to enhance supply chain functioning.
Genetic code surpasses computer code in complexity, indicating that genetic code required a more intelligent faculty to create it than did computer code. Genetic code is more complex because it is capable of imprinting data and passing it on to a new offspring resembling the parent. This simple fact humbles the best efforts of Steve Wozniak, Bill Gates and so on. For this reason, I humbly respect the vast Creation executed by the greatest Program Creator in the universe.
a reply to: cooperton
Self assembly is self coding. Self assembled nucleotides which organize molecular assembly are obviously self coded or they would be static and non-functional.
Letter | Published: 17 January 2008
Programming biomolecular self-assembly pathways
Peng Yin, Harry M. T. Choi, Colby R. Calvert & Niles A. Pierce
www.nature.com...
Gamma Peptide Nucleic Acids: As Orthogonal Nucleic Acid Recognition Codes for Organizing Molecular Self-Assembly
pubs.acs.org...
According to your theory code can self-assemble. But according to logic the genetic code could not have self-assembled into a coherent coding system. There are hundreds of proteins necessary for the first life. These proteins would have needed a meticulous precise coding to assimilate the proper amino acid sequence that would allow a viable cell. This insurmountable leap would be similar to a gorilla writing the entire code for the first apple computer from scratch.
Self assembly is self coding. Self assembled nucleotides which organize molecular assembly are obviously self coded or they would be static and non-functional.
Letter | Published: 17 January 2008
Programming biomolecular self-assembly pathways
Peng Yin, Harry M. T. Choi, Colby R. Calvert & Niles A. Pierce
Abstract
In contrast, attempts to rationally encode structure and function into synthetic amino acid and nucleic acid sequences have largely focused on engineering molecules that self-assemble into prescribed target structures, rather than on engineering transient system dynamics1,2. To design systems that perform dynamic functions without human intervention, it is necessary to encode within the biopolymer sequences the reaction pathways by which self-assembly occurs. Nucleic acids show promise as a design medium for engineering dynamic functions, including catalytic hybridization3,4,5,6, triggered self-assembly7 and molecular computation8,9. Here, we program diverse molecular self-assembly and disassembly pathways using a ‘reaction graph’ abstraction to specify complementarity relationships between modular domains in a versatile DNA hairpin motif. Molecular programs are executed for a variety of dynamic functions: catalytic formation of branched junctions, autocatalytic duplex formation by a cross-catalytic circuit, nucleated dendritic growth of a binary molecular ‘tree’, and autonomous locomotion of a bipedal walker.
In nature, self-assembling and disassembling complexes of proteins and nucleic acids bound to a variety of ligands perform intricate and diverse dynamic functions.
www.nature.com...
Gamma Peptide Nucleic Acids: As Orthogonal Nucleic Acid Recognition Codes for Organizing Molecular Self-Assembly
Nucleic acids are an attractive platform for organizing molecular self-assembly because of their specific nucleobase interactions and defined length scale. Routinely employed in the organization and assembly of materials in vitro, however, they have rarely been exploited in vivo, due to the concerns for enzymatic degradation and cross-hybridization with the host’s genetic materials. Herein we report the development of a tight-binding, orthogonal, synthetically versatile, and informationally interfaced nucleic acid platform for programming molecular interactions, with implications for in vivo molecular assembly and computing. The system consists of three molecular entities: the right-handed and left-handed conformers and a nonhelical domain. The first two are orthogonal to each other in recognition, while the third is capable of binding to both, providing a means for interfacing the two conformers as well as the natural nucleic acid biopolymers (i.e., DNA and RNA). The three molecular entities are prepared from the same monomeric chemical scaffold, with the exception of the stereochemistry or lack thereof at the γ-backbone that determines if the corresponding oligo adopts a right-handed or left-handed helix, or a nonhelical motif.
These conformers hybridize to each other with exquisite affinity, sequence selectivity, and level of orthogonality. Recognition modules as short as five nucleotides in length are capable of organizing molecular assembly.
pubs.acs.org...
edit on 21-1-2019 by Phantom423 because: (no reason given)
originally posted by: Phantom423
a reply to: cooperton
According to your theory code can self-assemble. But according to logic the genetic code could not have self-assembled into a coherent coding system. There are hundreds of proteins necessary for the first life. These proteins would have needed a meticulous precise coding to assimilate the proper amino acid sequence that would allow a viable cell. This insurmountable leap would be similar to a gorilla writing the entire code for the first apple computer from scratch.
Self assembly is self coding. Self assembled nucleotides which organize molecular assembly are obviously self coded or they would be static and non-functional.
Letter | Published: 17 January 2008
Programming biomolecular self-assembly pathways
Peng Yin, Harry M. T. Choi, Colby R. Calvert & Niles A. Pierce
Abstract
In contrast, attempts to rationally encode structure and function into synthetic amino acid and nucleic acid sequences have largely focused on engineering molecules that self-assemble into prescribed target structures, rather than on engineering transient system dynamics1,2. To design systems that perform dynamic functions without human intervention, it is necessary to encode within the biopolymer sequences the reaction pathways by which self-assembly occurs. Nucleic acids show promise as a design medium for engineering dynamic functions, including catalytic hybridization3,4,5,6, triggered self-assembly7 and molecular computation8,9. Here, we program diverse molecular self-assembly and disassembly pathways using a ‘reaction graph’ abstraction to specify complementarity relationships between modular domains in a versatile DNA hairpin motif. Molecular programs are executed for a variety of dynamic functions: catalytic formation of branched junctions, autocatalytic duplex formation by a cross-catalytic circuit, nucleated dendritic growth of a binary molecular ‘tree’, and autonomous locomotion of a bipedal walker.
In nature, self-assembling and disassembling complexes of proteins and nucleic acids bound to a variety of ligands perform intricate and diverse dynamic functions.
www.nature.com...
Gamma Peptide Nucleic Acids: As Orthogonal Nucleic Acid Recognition Codes for Organizing Molecular Self-Assembly
Nucleic acids are an attractive platform for organizing molecular self-assembly because of their specific nucleobase interactions and defined length scale. Routinely employed in the organization and assembly of materials in vitro, however, they have rarely been exploited in vivo, due to the concerns for enzymatic degradation and cross-hybridization with the host’s genetic materials. Herein we report the development of a tight-binding, orthogonal, synthetically versatile, and informationally interfaced nucleic acid platform for programming molecular interactions, with implications for in vivo molecular assembly and computing. The system consists of three molecular entities: the right-handed and left-handed conformers and a nonhelical domain. The first two are orthogonal to each other in recognition, while the third is capable of binding to both, providing a means for interfacing the two conformers as well as the natural nucleic acid biopolymers (i.e., DNA and RNA). The three molecular entities are prepared from the same monomeric chemical scaffold, with the exception of the stereochemistry or lack thereof at the γ-backbone that determines if the corresponding oligo adopts a right-handed or left-handed helix, or a nonhelical motif.
These conformers hybridize to each other with exquisite affinity, sequence selectivity, and level of orthogonality. Recognition modules as short as five nucleotides in length are capable of organizing molecular assembly.
pubs.acs.org...
To extend the analogy. A gorilla can type on a computer just like monomers can sometimes self-assemble given proper conditions. This does not mean a gorilla could type coherent computer code, nor could blind assembly of monomers ever create a coherent nucleic acid sequence from scratch.
Take for example the Titin protein, it is coded for by over 33,000 nucleic acids. For these meticulous sequence of nucleic acids to assemble in such a precise order would be like a gorilla writing a Shakespearean epic.
edit on 21-1-2019 by cooperton because: (no reason given)
a reply to: Phantom423
Self-Assembled DNA/Peptide-Based Nanoparticle Exhibiting Synergistic Enzymatic Activity
pubs.acs.org...
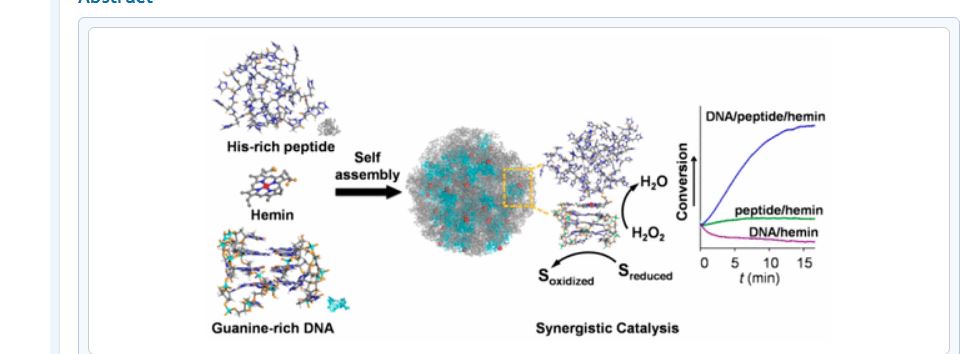
Self-Assembled DNA/Peptide-Based Nanoparticle Exhibiting Synergistic Enzymatic Activity
pubs.acs.org...
Designing enzyme-mimicking active sites in artificial systems is key to achieving catalytic efficiencies rivaling those of natural enzymes and can provide valuable insight in the understanding of the natural evolution of enzymes. Here, we report the design of a catalytic hemin-containing nanoparticle with self-assembled guanine-rich nucleic acid/histidine-rich peptide components that mimics the active site and peroxidative activity of hemoproteins. The chemical complementarities between the folded nucleic acid and peptide enable the spatial arrangement of essential elements in the active site and effective activation of hemin. As a result, remarkable synergistic effects of nucleic acid and peptide on the catalytic performances were observed. The turnover number of peroxide reached the order of that of natural peroxidase, and the catalytic efficiency is comparable to that of myoglobin. These results have implications in the precise design of supramolecular enzyme mimetics, particularly those with hierarchical active sites. The assemblies we describe here may also resemble an intermediate in the evolution of contemporary enzymes from the catalytic RNA of primitive cells.
a reply to: cooperton
You don't know any of that. Did you test it in the lab yourself? You're speculating on something that you haven't done.
And you missed the point of my post completely - The point is that DNA is a self assembled, self sustaining, self replicating molecule. A computer and/or computer code is not. The big gorilla in the room is that you're attempting to divert the original thesis into something entirely different. No go.
To extend the analogy. A gorilla can type on a computer just like monomers can sometimes self-assemble given proper conditions. This does not mean a gorilla could type coherent computer code, nor could blind assembly of monomers ever create a coherent nucleic acid sequence from scratch. Take for example the Titin protein, it is coded for by over 33,000 nucleic acids. For these meticulous sequence of nucleic acids to assemble in such a precise order would be like a gorilla writing a Shakespearean epic.
You don't know any of that. Did you test it in the lab yourself? You're speculating on something that you haven't done.
And you missed the point of my post completely - The point is that DNA is a self assembled, self sustaining, self replicating molecule. A computer and/or computer code is not. The big gorilla in the room is that you're attempting to divert the original thesis into something entirely different. No go.
originally posted by: Phantom423
a reply to: Phantom423
Self-Assembled DNA/Peptide-Based Nanoparticle Exhibiting Synergistic Enzymatic Activity
pubs.acs.org...
Designing enzyme-mimicking active sites in artificial systems is key to achieving catalytic efficiencies rivaling those of natural enzymes and can provide valuable insight in the understanding of the natural evolution of enzymes. Here, we report the design of a catalytic hemin-containing nanoparticle with self-assembled guanine-rich nucleic acid/histidine-rich peptide components that mimics the active site and peroxidative activity of hemoproteins. The chemical complementarities between the folded nucleic acid and peptide enable the spatial arrangement of essential elements in the active site and effective activation of hemin. As a result, remarkable synergistic effects of nucleic acid and peptide on the catalytic performances were observed. The turnover number of peroxide reached the order of that of natural peroxidase, and the catalytic efficiency is comparable to that of myoglobin. These results have implications in the precise design of supramolecular enzyme mimetics, particularly those with hierarchical active sites. The assemblies we describe here may also resemble an intermediate in the evolution of contemporary enzymes from the catalytic RNA of primitive cells.
This article doesn't have public access, and you only quoted the abstract. You need to read the methods of these papers to get a full understanding of the conditions they used. It is likely artificial conditions that do not represent normal conditions. It is also unlikely that any sort of self-assembly, even if by miracle they assembled into a 5000bp protein-coding sequence, would be able to survive long enough for the hundreds of other necessary proteins required for cell viability. Regardless, if you want a discussion, you need to find a paper that has public access.
originally posted by: Phantom423
You don't know any of that. Did you test it in the lab yourself? You're speculating on something that you haven't done.
No but countless attempts to replicate even making ONE, of the many, many many nucleic acid sequences required for the first life has not been demonstrated in a lab. Sure nucleic acids can probably self-assemble under meticulously controlled lab settings but none have demonstrated that this self-assembly can make a viable protein, let alone the hundreds of necessary proteins required for the viability of a cell.
And you missed the point of my post completely - The point is that DNA is a self assembled, self sustaining, self replicating molecule. A computer and/or computer code is not. The big gorilla in the room is that you're attempting to divert the original thesis into something entirely different. No go.
Never was arguing that. The gorilla writing the computer code was analogous to random nucleic acid assembly. The gorilla doesn't know how to code programs, nor does nucleic acid self-assembly 'know how' to create the titin protein. The titin nucleic acid sequence required meticulous programming, because it is a very precise protein that is one of the many components required for a functioning muscle.
edit on 21-1-2019 by cooperton because: (no reason given)
a reply to: cooperton
ACS does not allow sharing entire articles unless approved by the author(s) - these authors are Chinese and have not authorized sharing. However, I can give you a synopsis of how the samples were prepared which is below. But without the official Materials and Methods, it's hard to decipher how it was done. Analysis was primarily spectroscopic.
ACS does not allow sharing entire articles unless approved by the author(s) - these authors are Chinese and have not authorized sharing. However, I can give you a synopsis of how the samples were prepared which is below. But without the official Materials and Methods, it's hard to decipher how it was done. Analysis was primarily spectroscopic.
Note S1. Setup of theoretical models
The earlier studies on DzI (5’-GGGTTGGGCGGGATGGG-3’) and Bcl-2 (5’GGGCGGGTTAAGGAGGGCGCGGG-3’) G-quadruplexes binding hemin show that DNA provides axial coordination of the heme, probably using a nucleobase.1,2 However, there’s no high-resolution structure exists to date for DzI. Thus we built the DzI structure on the basis of the high-resolution NMR structures of Bcl-2(pdb:2f8U)3 by keeping the G-quadruplexes and replacing the loop nucleobases that linked the G-quadruplexes. The poly-histidine was built as a linear structure with 32 His residues and the ligand Fe(III) protoporphyrin IX (pdb:2QSP)4 from the structure of bovine hemoglobin was used in the following calculations. . Note S2. QM computation.
The structures of hemin and the activation center were optimized with Gaussian 09 program5 and the stationary points were confirmed to be minima by vibrational analysis. All the calculations were carried out at the B3LYP/6-31G*6,7 level of Density Functional Theory (DFT)8-11 . Note S3. Molecular dynamics simulations All the MD simulations were performed using the Gromacs 5.0 package12,13 combined with the AMBER03 force field14 and TIP4P solvent model15 . Na+ was used as counter ions to neutralize the systems After an initial steepest descent minimization of 50000 steps with the stepsize of 0.01 nm, the systems were then heated gradually from 0 to 300 K in the NVT ensemble for 100 ps and equilibrated at 300 K for 200 ps in the NPT ensemble. 50 ns production MD simulations were performed for the DNA and peptide, and 200 ns for the DNA-peptide complex at a constant temperature of 300 K and a constant pressure of 1 atm. The temperature and pressure of the system were maintained using V-rescale thermostat16 and isothermal-isobaric ensemble17, respectively. Particle Mesh Ewald (PME)18 was employed to deal with the long-range electrostatic interactions under periodic boundary conditions. The coordinates were saved every 10 ps for the subsequent analysis
Note S4. Molecular docking The peptide H32 and DNA DzI from the MD simulation were used for docking. The docked structures of the Heme-DNA and peptide-DNA complexes were used as the starting conformation for MD simulations. The molecular docking simulation was carried out by using Auto-Dock 4.2.6 and AutoDockTools 1.5.619 was employed to generate the docking input files and to analyze the docking results. To identify potential binding sites of the hemin on the peptide, a big grid box size of 126 × 126 × 126 points with a large spacing of 0.753 (DNA&peptide) and 0.375 Å (DNA&Heme) between the grid points was implemented and the grid box is big enough to cover the entire surface of the DNA. The ones with lowest binding energy were selected for the detailed analysis and further studies. The affinity maps of the DNA and peptide were calculated using AutoGrid. Lamarckian Genetic Algorithm (LGA) adds a local minimization to the genetic algorithm, enabling the modification of the gene population. The docking parameters are as follows: trials of 100 dockings, the population size of 150, the random starting position and conformation, the mutation rate of 0.02, the crossover rate of 0.8, the local search rate of 0.06, and 25 million energy evaluations. Final docked conformations were clustered using a tolerance of 1.5 Å root-mean-square deviations (RMSD).
a reply to: cooperton
This is not true. The abstract posted above demonstrates that nucleic acids which have self assembled are functional in a similar pattern as those observed in life forms.
No but countless attempts to replicate even making ONE, of the many, many many nucleic acid sequences required for the first life has not been demonstrated in a lab. Sure nucleic acids can probably self-assemble under meticulously controlled lab settings but none have demonstrated that this self-assembly can make a viable protein, let alone the hundreds of necessary proteins required for the viability of a cell.
This is not true. The abstract posted above demonstrates that nucleic acids which have self assembled are functional in a similar pattern as those observed in life forms.
originally posted by: Phantom423
This is not true. The abstract posted above demonstrates that nucleic acids which have self assembled are functional in a similar pattern as those observed in life forms.
They did not use conditions that would have been present in a pre-life earth. They used large peptides and pre-assembled nucleic acid sequences for docking:
"The docked structures of the Heme-DNA and peptide-DNA complexes were used as the starting conformation for MD simulations"
You see, they can't even replicate this process in a lab without already existent nucleic acid and protein sequences.
originally posted by: Phantom423
The abstract posted above demonstrates that nucleic acids which have self assembled are functional in a similar pattern as those observed in life forms.
The experiment you presented is using a theoretical computer model.
originally posted by: Phantom423
"The coordinates were saved every 10 ps for the subsequent analysis"
From the excerpts you posted^ it was not an actual experiment, it was a computer simulation. Further proving the genetic code is very similar to a computer algorithm.
edit on 21-1-2019 by cooperton because: (no reason given)
a reply to: cooperton
Refer to the other articles as well. This has been done.
You're not reading it correctly. Every experiment uses computer simulation today mostly for error correction.
Refer to the other articles as well. This has been done.
From the excerpts you posted^ it was not an actual experiment, it was a computer simulation. Further proving the genetic code is very similar to a computer algorithm.
You're not reading it correctly. Every experiment uses computer simulation today mostly for error correction.
edit on 21-1-2019 by
Phantom423 because: (no reason given)
originally posted by: Phantom423
You're not reading it correctly. Every experiment uses computer simulation today mostly for error correction.
The excerpt you showed me is clearly a simulation:
"The docked structures of the Heme-DNA and peptide-DNA complexes were used as the starting conformation for MD simulations. The molecular docking simulation was carried out by using Auto-Dock 4.2.6 and AutoDockTools 1.5.619 was employed to generate the docking input files and to analyze the docking results."
It is even titled:
"Note S1. Setup of theoretical models"
originally posted by: Phantom423
a reply to: cooperton
Yes - but as I said, you don't have access to Materials and Methods. That means you don't have access to the actual experiment, only to the theoretical setup.
Post the actual material and methods here then.
edit on 21-1-2019 by cooperton because: (no reason given)
originally posted by: cooperton
originally posted by: Barcs
. Go ahead and compare a programming language to the genetic code and show me some similarities.
Computer code is based on 1's and 0's.
And DNA code is not. Thanks for playing.
A binary yes or no option that serves as the basis for more complex coding. Similarly the genetic code has an A, G, T or C option for each of its positions in a coding sequence. These sequences code for a function called DNA polymerase, and other necessary programs, to come and parse the information and generate a functioning protein program that executes various functions throughout the organism. These processes have many fail-safes that prevent dangerous alterations from occurring, and it can even correct source-code errors on its own.
And that's all physical mechanisms. Computer software is not. Phantom absolutely destroyed you.
Epigenetics is a beautiful emerging field that shows the ability to amplify or diminish various parts of the source code (genetic code).
LOL @ romanticizing epigenetics while denying every other evolutionary mechanism. Epigenetic changes are changes to the physical structure of DNA that change gene expression. You keep repeating nonsensical arguments as if it conflicts with evolution when it does not.
that allows the biological computer to adapt to variable environments.
What biological computer? Just because there is a code, doesn't mean it is computer software.
This may seem like a deviation from computer code, but it is actually the epidome of what computer code wishes to accomplish
"Wishes to accomplish?" Come on, dude.
Genetic code surpasses computer code in complexity,
Irrelevant.
indicating that genetic code required a more intelligent faculty to create it than did computer code.
Complete assumption.
For this reason, I humbly respect the vast Creation executed by the greatest Program Creator in the universe.
Don't lie. The real reason is because you cherry pick anything that supports your faith and deny anything that does not, regardless of how well substantiated it is. You arguments aren't based on the quantity of supporting evidence in the slightest. It's based on emotional attachment to one particular world view.
edit on 1 22 19 by Barcs because: (no reason given)
originally posted by: Barcs
"Computer code is based on 1's and 0's"
And DNA code is not. Thanks for playing.
Haha well aren't you a grumpy little boy. Genetic code is a quaternary code instead of a binary code. Binary code can't retain enough data for mRNA transcription due to an insufficient number of combinations to code for all the different amino acids. So before I continue wasting my time explaining things to you, do you actually want to discuss things? Or do you just want to try to be right?
originally posted by: Barcs
Phantom absolutely destroyed you.
She posted a paper that she thought was evidence for self-assembly of monomers but it was actually a computer simulation. I don't think she owned me at all, we were actually having a pleasant back and forth conversation. It appears you just want to see me lose no matter what it takes. During real conversation, everyone wins.
edit on 22-1-2019 by cooperton because: (no reason given)
a reply to: cooperton
Correction: That paper was NOT a computer simulation, no matter how much you insist it is. You don't work in a modern lab so you don't know that every scientific experiment is subject to computer analysis including simulation. Algorithms are written to test the experiments, verify data and calculations and run "what if" scenarios. You know NOTHING about working in a modern lab so please don't pretend that you do. And DO NOT insinuate something that is not true.
In addition, you never addressed the other two papers that I posted. The Materials and Methods are clearly outlined in the full papers.
You think you found a needle in a haystack or a "gotcha" by insisting that the Chinese paper was a computer simulation. Well you DID NOT.
As regards the question about self assembly of nucleic acids and related functionality, there are many other papers, particularly in nanotechnology, that demonstrate the same idea. If I have a chance tomorrow, I will post several - although I doubt you will read them.
Don't you get tired of displaying your ignorance. You really outed yourself with this one - you haven't a clue how modern scientific investigation works. You really slipped in it............
She posted a paper that she thought was evidence for self-assembly of monomers but it was actually a computer simulation. I don't think she owned me at all, we were actually having a pleasant back and forth conversation. It appears you just want to see me lose no matter what it takes. During real conversation, everyone wins.
Correction: That paper was NOT a computer simulation, no matter how much you insist it is. You don't work in a modern lab so you don't know that every scientific experiment is subject to computer analysis including simulation. Algorithms are written to test the experiments, verify data and calculations and run "what if" scenarios. You know NOTHING about working in a modern lab so please don't pretend that you do. And DO NOT insinuate something that is not true.
In addition, you never addressed the other two papers that I posted. The Materials and Methods are clearly outlined in the full papers.
You think you found a needle in a haystack or a "gotcha" by insisting that the Chinese paper was a computer simulation. Well you DID NOT.
As regards the question about self assembly of nucleic acids and related functionality, there are many other papers, particularly in nanotechnology, that demonstrate the same idea. If I have a chance tomorrow, I will post several - although I doubt you will read them.
Don't you get tired of displaying your ignorance. You really outed yourself with this one - you haven't a clue how modern scientific investigation works. You really slipped in it............
originally posted by: Phantom423
Correction: That paper was NOT a computer simulation, no matter how much you insist it is.
look girl, I would love to have some good philosophical debate regarding all your cherished points of view, but you keep sending me garbage that has no basis in reality... Please, seriously please, don't take this as malcontent. The paper you presented was at least, in majority, in regards to a computer simulation. Ironically proving the point that genetic code is similar to how computer code works. It doesn't matter though... I just hope you are OK... we are human after all,
edit on 22-1-2019 by cooperton because: (no reason given)
new topics
-
Big Storms
Fragile Earth: 1 hours ago -
Where should Trump hold his next rally
2024 Elections: 4 hours ago -
Shocking Number of Voters are Open to Committing Election Fraud
US Political Madness: 4 hours ago -
Gov Kristi Noem Shot and Killed "Less Than Worthless Dog" and a 'Smelly Goat
2024 Elections: 5 hours ago -
Falkville Robot-Man
Aliens and UFOs: 5 hours ago -
James O’Keefe: I have evidence that exposes the CIA, and it’s on camera.
Whistle Blowers and Leaked Documents: 6 hours ago -
Australian PM says the quiet part out loud - "free speech is a threat to democratic dicourse"...?!
New World Order: 7 hours ago -
Ireland VS Globalists
Social Issues and Civil Unrest: 7 hours ago -
Biden "Happy To Debate Trump"
2024 Elections: 8 hours ago -
RAAF airbase in Roswell, New Mexico is on fire
Aliens and UFOs: 8 hours ago
top topics
-
James O’Keefe: I have evidence that exposes the CIA, and it’s on camera.
Whistle Blowers and Leaked Documents: 6 hours ago, 13 flags -
Blast from the past: ATS Review Podcast, 2006: With All Three Amigos
Member PODcasts: 10 hours ago, 13 flags -
Australian PM says the quiet part out loud - "free speech is a threat to democratic dicourse"...?!
New World Order: 7 hours ago, 12 flags -
Biden "Happy To Debate Trump"
2024 Elections: 8 hours ago, 12 flags -
Mike Pinder The Moody Blues R.I.P.
Music: 10 hours ago, 8 flags -
What is the white pill?
Philosophy and Metaphysics: 9 hours ago, 6 flags -
RAAF airbase in Roswell, New Mexico is on fire
Aliens and UFOs: 8 hours ago, 5 flags -
Ireland VS Globalists
Social Issues and Civil Unrest: 7 hours ago, 5 flags -
Shocking Number of Voters are Open to Committing Election Fraud
US Political Madness: 4 hours ago, 5 flags -
Where should Trump hold his next rally
2024 Elections: 4 hours ago, 4 flags
active topics
-
Post A Funny (T&C Friendly) Pic Part IV: The LOL awakens!
General Chit Chat • 7138 • : baddmove -
Ireland VS Globalists
Social Issues and Civil Unrest • 8 • : nugget1 -
Gov Kristi Noem Shot and Killed "Less Than Worthless Dog" and a 'Smelly Goat
2024 Elections • 36 • : cherokeetroy -
Definitive 9.11 Pentagon EVIDENCE.
9/11 Conspiracies • 428 • : Zanti Misfit -
Gaza Terrorists Attack US Humanitarian Pier During Construction
Middle East Issues • 88 • : ToneD -
Falkville Robot-Man
Aliens and UFOs • 6 • : nugget1 -
"We're All Hamas" Heard at Columbia University Protests
Social Issues and Civil Unrest • 293 • : marg6043 -
So this is what Hamas considers 'freedom fighting' ...
War On Terrorism • 267 • : NorthOS -
President BIDEN Vows to Make Americans Pay More Federal Taxes in 2025 - Political Suicide.
2024 Elections • 146 • : Zanti Misfit -
Big Storms
Fragile Earth • 8 • : charlest2