It looks like you're using an Ad Blocker.
Please white-list or disable AboveTopSecret.com in your ad-blocking tool.
Thank you.
Some features of ATS will be disabled while you continue to use an ad-blocker.

L:lol:L what's with all these "prophets" of "nothing will happen"?
page: 10share:
reply to post by BlueMule
Sorry. That makes for the sort of pseudoscience that GCP is.
So you quote someone that can't publish in a real journal. So what?
Even the proponents of GCP have stated
So a failed experiment shows us what? It sounds like it shows us nothing has happened.
In case you were not aware, the experiment is unrelated to 2012.
Follow the data, not a theory.
Sorry. That makes for the sort of pseudoscience that GCP is.
So you quote someone that can't publish in a real journal. So what?
Even the proponents of GCP have stated
Nelson concedes "the data, so far, is not solid enough for global consciousness to be said to exist at all.
So a failed experiment shows us what? It sounds like it shows us nothing has happened.
In case you were not aware, the experiment is unrelated to 2012.
edit on 3-1-2013 by stereologist because: (no reason given)
Originally posted by stereologist
reply to post by BlueMule
Follow the data, not a theory.
Sorry. That makes for the sort of pseudoscience that GCP is.
Sorry. Just saying that doesn't make it so.
Here's how it works. The GCP made a claim and provided evidence to support it. The evidence is "highly significant".
If you wish to respond by making a counter-claim then the burden falls to you.
So I will wait for you to go perform your own analysis of the GCP data so that you can support your counter-claim.
Otherwise... your armchair criticisms, dogmatic assertions, and scientism apologetics are worthless.
edit on 3-1-2013 by BlueMule because: (no reason given)
reply to post by BlueMule
The GCP has no highly significant data. That's the problem. They see occasional sequences that they try to tie to events. That's it. Even the insiders say they have little as I pointed out.
Already did that.
That makes your armchair support worthless.
Here's how it works. The GCP made a claim and provided evidence to support it. The evidence is "highly significant".
The GCP has no highly significant data. That's the problem. They see occasional sequences that they try to tie to events. That's it. Even the insiders say they have little as I pointed out.
If you wish to respond by making a counter-claim then the burden falls to you.
Already did that.
Otherwise... your armchair criticisms, dogmatic assertions, and scientism apologetics are worthless.
That makes your armchair support worthless.
Originally posted by stereologist
reply to post by BlueMule
Here's how it works. The GCP made a claim and provided evidence to support it. The evidence is "highly significant".
The GCP has no highly significant data.
I guess you missed it. Here it is again.
Graph of Accumulating Deviations: The Complete Formal Database
The two following figures represent the history of our formal hypothesis testing. The first shows the Z-scores for more than 350 formally specified events in an ordinary scatterplot. While there is a noticeable positive bias, it is not easy to see its significance. Yet the odds against chance of this meanshift over a database this size are about a thousand million to one.
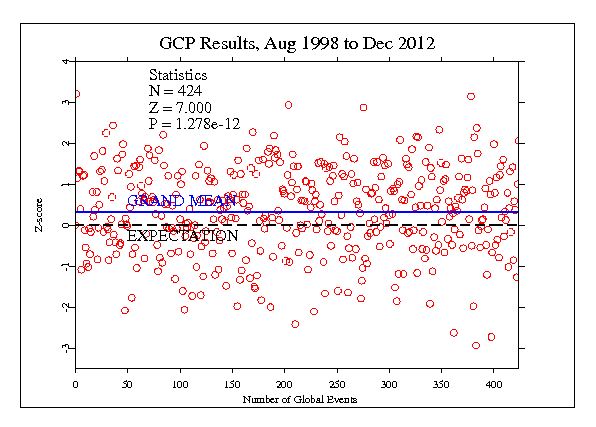
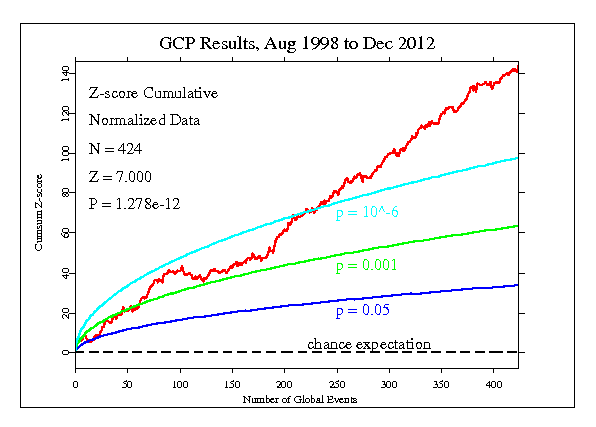
The second figure displays the same data as a cumulative deviation from chance expectation (shown as the horizontal black line at 0 deviation). Truly random data would produce a jagged curve with no slope, wandering up and down around the horizontal. The dotted smooth curves show the 0.05 and 0.001 and 0.000001 probability envelopes that indicate significant versus chance excursions. This figure can be compared with a "control distribution" using simulations of the event series.
The jagged red line shows the accumulating excess of the empirically normalized Z-scores relative to expectation for the complete dataset of rigorously defined events. The overall result is highly significant. The odds against chance are much greater than a million to one.
So, if you make the counter-claim that the overall results are not highly significant, then I would like to see you produce your own analysis of all the data the project has accumulated.
I repeat. YOUR OWN ANALYSIS.
Otherwise all you have is rhetoric.
In other words, put up or shut up.
edit on 3-1-2013 by BlueMule because: (no reason given)
reply to post by BlueMule
What is their methodology for objectively picking events of significance? Oh that's right, there isn't one. Also, spamming the same post across multiple threads and forums is against the site's TACs.
What is their methodology for objectively picking events of significance? Oh that's right, there isn't one. Also, spamming the same post across multiple threads and forums is against the site's TACs.
edit on 3-1-2013 by john_bmth because: (no reason given)
reply to post by john_bmth
Wow, this place is crawling with arrogant pseudo-skeptic mind-guards who think they know it all, isn't it?
Have you thought to read the FAQ, Mr "Skeptic"?
gcp.grama.co...
Wow, this place is crawling with arrogant pseudo-skeptic mind-guards who think they know it all, isn't it?
Have you thought to read the FAQ, Mr "Skeptic"?
gcp.grama.co...
edit on 3-1-2013 by BlueMule because: (no reason given)
Originally posted by BlueMule
reply to post by john_bmth
Wow, this place is crawling with arrogant pseudo-skeptical mind-guards who think they know it all, isn't it?
Have you thought to read the FAQ, Mr "Skeptic"?
gcp.grama.co...
1) Look up the term "pseudo". I don't think you know what it means.
2) Stop being hypocritical by insinuating other people are closed minded because they don't accept what you say unquestionably.
In other news, I'm not wading through pages and pages of FAQ answers, how about you go ahead and post the pertinent sections? Note: objective is the key word here.
edit on 3-1-2013 by john_bmth because: (no reason given)
reply to post by john_bmth
John, I'm not going to bother with you. You are clearly the worst kind of skeptic. You are the kind that isn't really a skeptic at all... but an apologist. A kind of fundamentalist. Not worth the trouble.
I don't believe in skeptics
John, I'm not going to bother with you. You are clearly the worst kind of skeptic. You are the kind that isn't really a skeptic at all... but an apologist. A kind of fundamentalist. Not worth the trouble.
I don't believe in skeptics
edit on 3-1-2013 by BlueMule because: (no reason given)
Originally posted by BlueMule
reply to post by john_bmth
John, I'm not going to bother with you. You are clearly the worst kind of skeptic. The kind that isn't really a skeptic at all but an apologist. A kind of fundamentalist. Not worth the trouble.
I don't believe in skeptics
edit on 3-1-2013 by BlueMule because: (no reason given)
So are you going to post their methodology for objectively picking events of significance? Or are you going to pack up your toys and go home as soon as people push you to rationalise and substantiate the baseless claims you've been spamming these boards with?
Classic charlatan's diversionary tactic of avoiding questions by making ad hominen attacks instead.
By the way, you should really read this site's Terms & Conditions:
15h.) Spamming: You will not Post identical content, or snippets of identical content, to multiple threads in the discussion forums. You will also not create more than one thread for your topic, or create multiple "slightly different" threads for a single topic.
edit on 3-1-2013 by
john_bmth because: (no reason given)
People like to post information that they often do not understand. They post something that sounds good and they have not a grain of understanding of
the issues at hand. Not a bit, but they defend them while being completely in the dark over the issues.
That straight red line just tells us that whatever is happening is dependent on time and nothing else. It happens at a fairly regular rate independent of the events around it.
The GCP is known for using poorly defined methods and lots of excuses. They claim failures are actual positive events. So when they get spikes before events, then the systems is predicting events instead of have these anomalies when nothing is happening. Similar dead beat excuses have been used such as the sheep goat effect and why pyramid power doesn't work and why more planes have gone missing over the continental US than in the Bermuda triangle.
That straight red line just tells us that whatever is happening is dependent on time and nothing else. It happens at a fairly regular rate independent of the events around it.
The GCP is known for using poorly defined methods and lots of excuses. They claim failures are actual positive events. So when they get spikes before events, then the systems is predicting events instead of have these anomalies when nothing is happening. Similar dead beat excuses have been used such as the sheep goat effect and why pyramid power doesn't work and why more planes have gone missing over the continental US than in the Bermuda triangle.
Some significant global events were:
The phillies winning the world series, michael Jackson dies and Ted Kennedy dies. I'm not sure that these are qualifying global events.
However, the phillies winning the world series was due to the placement of a small statue on the Comcast center. No Philadelphia team has won anything since the statue of penn on top of city hall was trumped as the tallest building. en.m.wikipedia.org...
Surely this is due to more than random chance.
The phillies winning the world series, michael Jackson dies and Ted Kennedy dies. I'm not sure that these are qualifying global events.
However, the phillies winning the world series was due to the placement of a small statue on the Comcast center. No Philadelphia team has won anything since the statue of penn on top of city hall was trumped as the tallest building. en.m.wikipedia.org...
Surely this is due to more than random chance.
here is a sample from the event registry
Here is my pseudo whatever I am impression of this. Its random data tied to subjectively selected "events". Selection of the "global events" is key here and seems to be the topic that is danced around the most on thier site. This is most likely where the whole thing falls apart. How something qualifies as an event is perplexing. How is this decided and by whom? Global Orgasm day? isnt that every day?
Another comment,or impression I get is that they are very wordy and technical instead of giving a straight answer. In other words, you have to know the lingo or pretend like you do and accept it. Its a good technique to throw off those that dont know the language. Being in IT, I do this often. Most people accept any answer you give them if it sounds too technical for them. "sorry I cant fix your computer becuase your ram in the motherboard ate 10 gigs hardrive space currupting the boot files. its microsoft"
from the faq
some things I have to brush up on...
random resampling
permutation analysis
full database statistical characterization
the brief answer? I learned absolutely nothing from this response
and then the folks that DO know better are left to sort through a mountain of data just to prove that its BS.
So it seems like they have all their bases covered. well done.
600 df weight Yes 279 Phillies Win World Series 2008-10-30 0:00:00 2008-10-30 02:29:59 1-sec Stouffer Z Chisquare
600 df weight Yes 280 US Election 2008 2008-11-04 20:00:00 2008-11-05 19:59:59 1-sec Stouffer Z Chisquare
600 df weight Yes 281 Mumbai Terror Attacks 2008-11-26 16:30:00 2008-11-27 16:29:59 1-sec Stouffer Z Chisquare
600 df weight Yes 282 Global Orgasm III 2008-12-21 00:00:00 2008-12-21 23:59:59 1-sec Stouffer Z Chisquare
Here is my pseudo whatever I am impression of this. Its random data tied to subjectively selected "events". Selection of the "global events" is key here and seems to be the topic that is danced around the most on thier site. This is most likely where the whole thing falls apart. How something qualifies as an event is perplexing. How is this decided and by whom? Global Orgasm day? isnt that every day?
Another comment,or impression I get is that they are very wordy and technical instead of giving a straight answer. In other words, you have to know the lingo or pretend like you do and accept it. Its a good technique to throw off those that dont know the language. Being in IT, I do this often. Most people accept any answer you give them if it sounds too technical for them. "sorry I cant fix your computer becuase your ram in the motherboard ate 10 gigs hardrive space currupting the boot files. its microsoft"
from the faq
Have you picked a random event as a control and done an analysis of randomness based on that? If so, where might I find the results?
There is a full description of the statistical characterization of the data on the GCP website under the "scientific work" set of links. You can start with EGG data archive.(broken link) Some relevant points are discussed elsewhere in this FAQ
It is possible to pick a control "random event" as you suggest, but that is not a satisfactory way to address the implied question. We use the more powerful techniques of random resampling, permutation analysis, and full database statistical characterization. For some purposes, e.g., to establish statistical independence of measures, we use simulations and modeling.
some things I have to brush up on...
random resampling
permutation analysis
full database statistical characterization
The brief answer to your question is that the normalized data do show expected values across the full database in all moments of the appropriate statistical distributions. The same is true of the individual physical random sources and their composite, and it is true for each of the measures we use in the hypothesis testing. This is the background. Against that background, the replicated hypothesis tests in the formal series show departures from expectation, with a composite Z-score of about 4.5 (May 2007).
the brief answer? I learned absolutely nothing from this response
and then the folks that DO know better are left to sort through a mountain of data just to prove that its BS.
So it seems like they have all their bases covered. well done.
edit on 4-1-2013 by ZetaRediculian because: (no reason
given)
edit on 4-1-2013 by ZetaRediculian because: (no reason given)
edit on 4-1-2013 by ZetaRediculian because: (no
reason given)
reply to post by BlueMule
I found this answer to the question in the faq
The answer seems to be that there is no method but they do include India
Originally posted by john_bmth
reply to post by BlueMule
What is their methodology for objectively picking events of significance? Oh that's right, there isn't one. Also, spamming the same post across multiple threads and forums is against the site's TACs.edit on 3-1-2013 by john_bmth because: (no reason given)
Have you thought to read the FAQ, Mr "Skeptic"?
I found this answer to the question in the faq
How do you choose which "events" to count and which not? The GCP has consistently ignored many major events of high spiritual value with 1 to 20 x 10^6 people in India. e.g., India was left out of the analyses all together, as far as I know, even though they account for about 1/6 of the world's population.
In fact, India figures prominently in several formal predictions: India, Train Crash, 990801, Typhoon, India, 2 Hours, 991029, Typhoon, India, 24 Hours, 991029-30, Just A Minute, 1 Min Epoch, 20000101, Kumbh Mela, India, 20010124 and in several more exploratory analyses, including the elections in October 1999. The GCP does not pretend to assess all worthwhile/reasonable/major events, but we definitely have not ignored India.
The answer seems to be that there is no method but they do include India
I guess he doesn't want to discuss objectively or respond to my comments but would rather spam the place with bogus data. Oh well
reply to post by ZetaRediculian
Of course not, he/she has explicitly stated that he/she will not discuss with "debunkers" and "pseudo-skeptics". Evidently his/her convictions aren't string enough to weather serious scrutiny.
Of course not, he/she has explicitly stated that he/she will not discuss with "debunkers" and "pseudo-skeptics". Evidently his/her convictions aren't string enough to weather serious scrutiny.
reply to post by john_bmth
Well, I am neither a skeptic nor a debunker. I just like to prove things wrong that claim to show things that they don't. This was an easy one.
Well, I am neither a skeptic nor a debunker. I just like to prove things wrong that claim to show things that they don't. This was an easy one.
Originally posted by ZetaRediculian
reply to post by john_bmth
Well, I am neither a skeptic nor a debunker.
The very act of disagreeing with BlueMule makes you a "debunker" and a "pseudo-skeptic" in his/her mind.
reply to post by john_bmth
I've noticed that too.
It's too bad that BlueMule makes it so easy to disagree with him/her.
The very act of disagreeing with BlueMule makes you a "debunker" and a "pseudo-skeptic" in his/her mind.
I've noticed that too.
It's too bad that BlueMule makes it so easy to disagree with him/her.
new topics
-
Where should Trump hold his next rally
Politicians & People: 38 minutes ago -
Shocking Number of Voters are Open to Committing Election Fraud
US Political Madness: 1 hours ago -
Gov Kristi Noem Shot and Killed "Less Than Worthless Dog" and a 'Smelly Goat
2024 Elections: 2 hours ago -
Falkville Robot-Man
Aliens and UFOs: 2 hours ago -
James O’Keefe: I have evidence that exposes the CIA, and it’s on camera.
Whistle Blowers and Leaked Documents: 3 hours ago -
Australian PM says the quiet part out loud - "free speech is a threat to democratic dicourse"...?!
New World Order: 3 hours ago -
Ireland VS Globalists
Social Issues and Civil Unrest: 4 hours ago -
Biden "Happy To Debate Trump"
2024 Elections: 4 hours ago -
RAAF airbase in Roswell, New Mexico is on fire
Aliens and UFOs: 5 hours ago -
What is the white pill?
Philosophy and Metaphysics: 6 hours ago
top topics
-
A Warning to America: 25 Ways the US is Being Destroyed
New World Order: 14 hours ago, 21 flags -
Blast from the past: ATS Review Podcast, 2006: With All Three Amigos
Member PODcasts: 7 hours ago, 11 flags -
Mike Pinder The Moody Blues R.I.P.
Music: 7 hours ago, 8 flags -
Biden "Happy To Debate Trump"
2024 Elections: 4 hours ago, 8 flags -
Australian PM says the quiet part out loud - "free speech is a threat to democratic dicourse"...?!
New World Order: 3 hours ago, 7 flags -
James O’Keefe: I have evidence that exposes the CIA, and it’s on camera.
Whistle Blowers and Leaked Documents: 3 hours ago, 6 flags -
What is the white pill?
Philosophy and Metaphysics: 6 hours ago, 5 flags -
Ireland VS Globalists
Social Issues and Civil Unrest: 4 hours ago, 4 flags -
RAAF airbase in Roswell, New Mexico is on fire
Aliens and UFOs: 5 hours ago, 4 flags -
Putin, Russia and the Great Architects of the Universe
ATS Skunk Works: 10 hours ago, 3 flags
active topics
-
Where should Trump hold his next rally
Politicians & People • 4 • : gortex -
University of Texas Instantly Shuts Down Anti Israel Protests
Education and Media • 305 • : Xtrozero -
Biden "Happy To Debate Trump"
2024 Elections • 38 • : JadedGhost -
Russia Ukraine Update Thread - part 3
World War Three • 5737 • : Arbitrageur -
Gov Kristi Noem Shot and Killed "Less Than Worthless Dog" and a 'Smelly Goat
2024 Elections • 26 • : CarlLaFong -
James O’Keefe: I have evidence that exposes the CIA, and it’s on camera.
Whistle Blowers and Leaked Documents • 8 • : Athetos -
Weinstein's conviction overturned
Mainstream News • 29 • : Xtrozero -
Shocking Number of Voters are Open to Committing Election Fraud
US Political Madness • 2 • : xuenchen -
Candidate TRUMP Now Has Crazy Judge JUAN MERCHAN After Him - The Stormy Daniels Hush-Money Case.
Political Conspiracies • 810 • : Annee -
Do you ever just get "bored" of everything?
Rant • 22 • : JonnyC555