It looks like you're using an Ad Blocker.
Please white-list or disable AboveTopSecret.com in your ad-blocking tool.
Thank you.
Some features of ATS will be disabled while you continue to use an ad-blocker.

UFO / IFO images : Coding challenge - batch reverse image searches (Python / Selenium?)
page: 1share:
SECTION A : INTRODUCTION
SECTION B : SAMPLE SET OF IMAGES (FROM MICHAEL HUNTINGTON’S ARCHIVES)
SECTION C : SOCIAL MEDIA AND IMAGE DATA
SECTION D : REVERSE IMAGE SEARCHES AND CODING
SECTION E : CODE TO CREATE SCREENSHOTS OF A LIST OF URL
SECTION F : COMBINING THE ABOVE - CREATING SCREENSHOTS OF RESULTS?
SECTION A : INTRODUCTION
As some of you may know, I’ve worked over the years to create various tools and archives for the UFO community (particularly making freely available online over 2 million pages of scans of official documents, defunct UFO magazines/newsletters, automated transcripts of UFO podcasts/documentaries and other material). Details of those projects can be found in my previous posts on ATS over the last decade or so, and on my blog.
I’d now like (ideally with a bit of help from others, particularly those with a bit more coding experience – probably, but not necessarily, with Python/Selenium…) to develop a new archiving method for UFO material. This relates to images of UFOs/IFOs and related information. I think this possibility has considerable potential to help improve some aspects of UFO research. It’s worth a try anyway...
In short, I’d like to combine code that enables reverse image search results to be generated from locally stored images (see SECTION D below) with code that enables the taking of snapshots of webpages (see SECTION E below).
Since both sets of codes already exist, I’m hoping that combining the two will be relatively simple (famous last words, I know…) and allow the batch creation of an archive of the results of reverse image searches on tens of thousands of UFO/IFO images.
I think this may enable anyone to have their computer go through a folder full of images (such as in the first image below – say, IMAGE1.jpg) and batch generate reverse image search results (such as in the second image below), saving the latter with a related file name (say, IMAGE1 RESULTS.jpg), so that both images can be converted into consecutive pages of a searchable PDF.

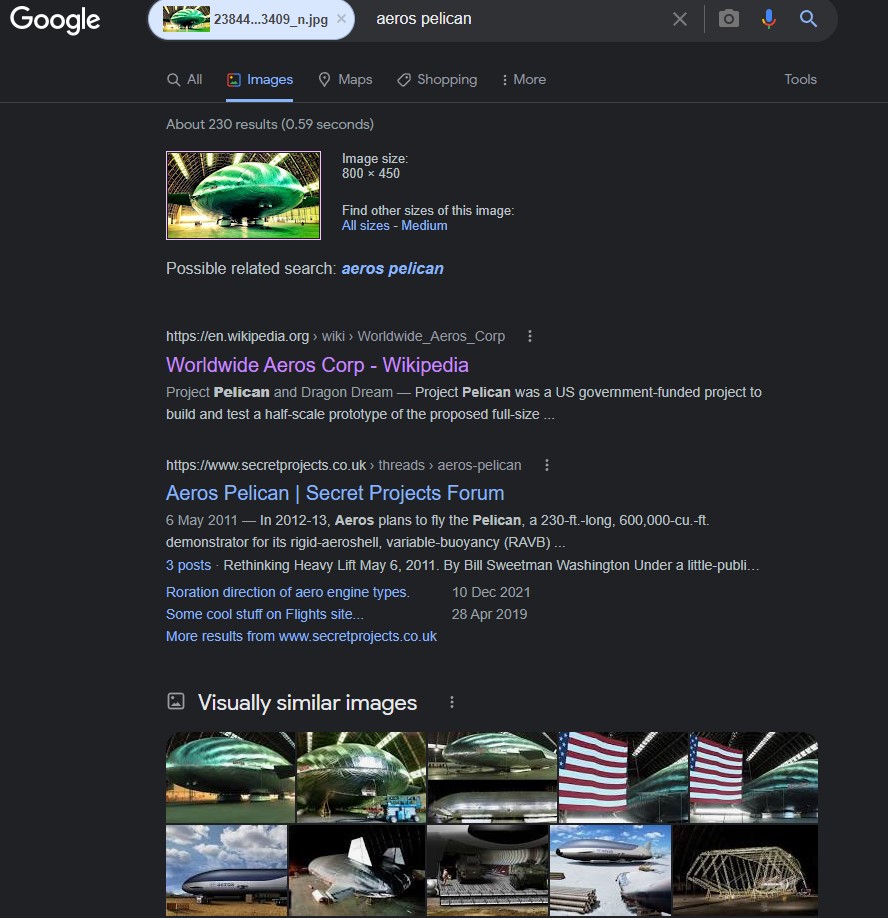
I’ve uploaded a small sample set of images (about 2,000 images) so that this discussion to enable testing/demonstrations and outline some thoughts and problems below.
I’m hoping that combining the two sets of codes may boil down to just a few lines of code – almost certainly much shorter than these opening post – but it’s probably worth my highlighting the existing codes that I’ve found.
(When providing any suggestions for code, please keep in mind that I’m just a lawyer so may need a bit of spoon-feeding…).
SECTION B : SAMPLE SET OF IMAGES (FROM MICHAEL HUNTINGTON’S ARCHIVES)
SECTION C : SOCIAL MEDIA AND IMAGE DATA
SECTION D : REVERSE IMAGE SEARCHES AND CODING
SECTION E : CODE TO CREATE SCREENSHOTS OF A LIST OF URL
SECTION F : COMBINING THE ABOVE - CREATING SCREENSHOTS OF RESULTS?
SECTION A : INTRODUCTION
As some of you may know, I’ve worked over the years to create various tools and archives for the UFO community (particularly making freely available online over 2 million pages of scans of official documents, defunct UFO magazines/newsletters, automated transcripts of UFO podcasts/documentaries and other material). Details of those projects can be found in my previous posts on ATS over the last decade or so, and on my blog.
I’d now like (ideally with a bit of help from others, particularly those with a bit more coding experience – probably, but not necessarily, with Python/Selenium…) to develop a new archiving method for UFO material. This relates to images of UFOs/IFOs and related information. I think this possibility has considerable potential to help improve some aspects of UFO research. It’s worth a try anyway...
In short, I’d like to combine code that enables reverse image search results to be generated from locally stored images (see SECTION D below) with code that enables the taking of snapshots of webpages (see SECTION E below).
Since both sets of codes already exist, I’m hoping that combining the two will be relatively simple (famous last words, I know…) and allow the batch creation of an archive of the results of reverse image searches on tens of thousands of UFO/IFO images.
I think this may enable anyone to have their computer go through a folder full of images (such as in the first image below – say, IMAGE1.jpg) and batch generate reverse image search results (such as in the second image below), saving the latter with a related file name (say, IMAGE1 RESULTS.jpg), so that both images can be converted into consecutive pages of a searchable PDF.
I’ve uploaded a small sample set of images (about 2,000 images) so that this discussion to enable testing/demonstrations and outline some thoughts and problems below.
I’m hoping that combining the two sets of codes may boil down to just a few lines of code – almost certainly much shorter than these opening post – but it’s probably worth my highlighting the existing codes that I’ve found.
(When providing any suggestions for code, please keep in mind that I’m just a lawyer so may need a bit of spoon-feeding…).
edit on 24-2-2022 by IsaacKoi because: (no reason given)
edit on 24-2-2022 by IsaacKoi because: (no reason
given)
edit on 24-2-2022 by IsaacKoi because: (no reason given)
SECTION B : SAMPLE SET OF IMAGES (FROM MICHAEL HUNTINGTON’S ARCHIVES)
Michael Huntington is an American UFO researcher. Among other things, he posts a lot of images on on Facebook and on Twitter.
The Facebook collections are of particular interest to me because they are sorted into “albums”. Albums posted by UFO researchers on Facebook provide one means of easily obtaining relatively large sets of images already sorted into particular topics.
All the photos in a Facebook albums can be downloaded using tools such as the Chrome extension “Album Downloader for Facebook”. (Using such extensions can, however, be a bit fiddly. I had to run the tool about 30 times to eventually download 90% of the images, with Facebook twice suspending my access for a few minutes. This resulted in numerous duplicates of some files, which I eventually eliminated by searching for any files with brackets – using ~="*(*)*" – and then deleting them).
As part of a small test/demonstration, I've created a folder on the AFU’s website containing the photos from one of Michael Huntington's Facebook albums ("Clandestine Airspace"), with his kind permission. That album includes over 2,000 images – most of which are, I think, pretty cool.
Michael Huntington has explained the following to me in relation to his "Clandestine Airspace" album on Facebook:
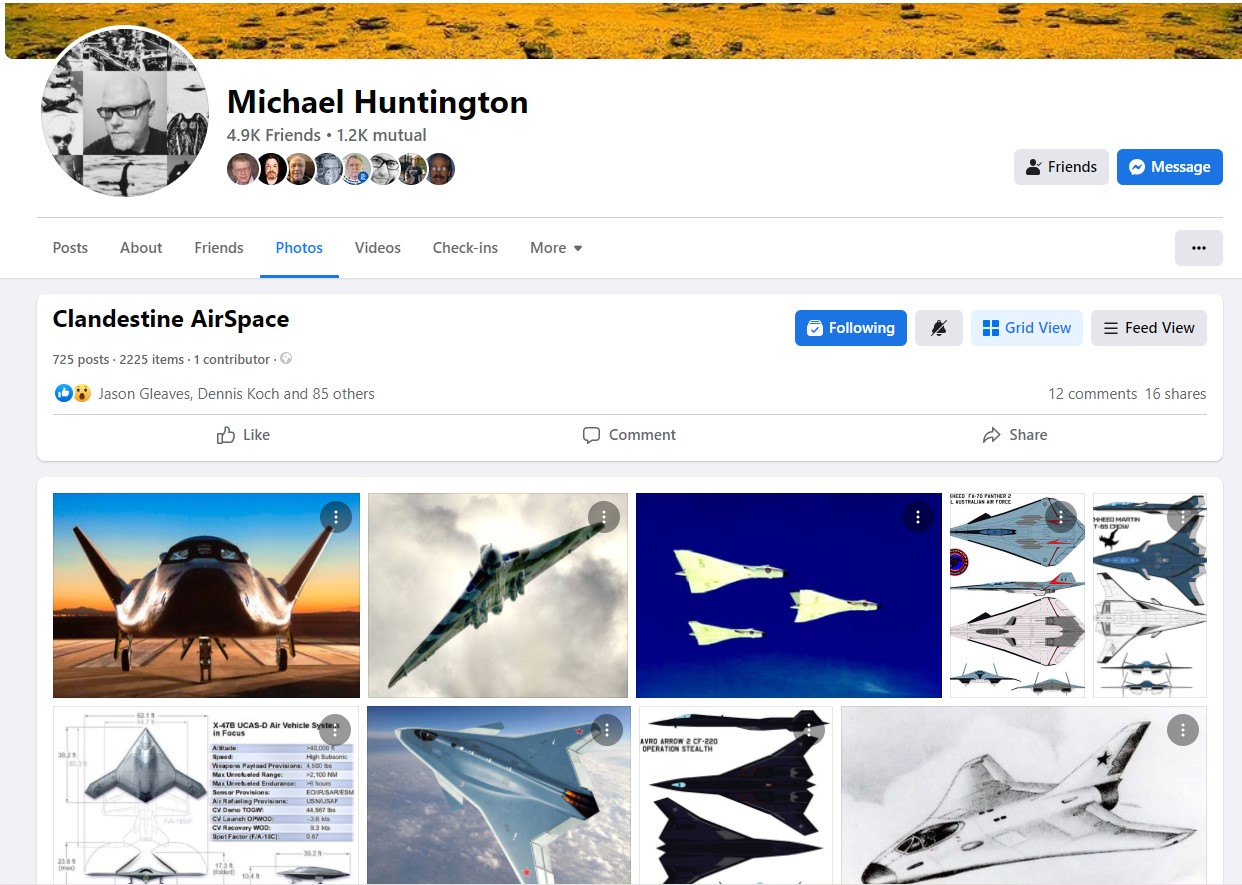
For example:

Michael Huntington's existing Facebook Album is better for simple browsing of that collection than the folder I’ve created, but the online folder of individual jpg images is more easily downloadable ... and potentially allows for a bit of fun - outlined below.
Firstly, and most simply, I've used the downloaded images to create a large PDF which incorporates all the relevant images uploaded so far and rendered it searchable for any text used in the images themselves (e.g. "drone" or "Russian"). I turned the collection of images into single PDFs using Adobe Acrobat and then used PDFSam Basic (a free piece of software) to join the images together into a single PDF (ticking an option to create one bookmarks for each file merged into the new PDF). This means that each page of the PDF has a bookmark indicating the file name of the relevant image - just click on the option to display bookmarks in your preferred PDF viewer.
Secondly (and this is the bit with more potential, but not entirely straightforward – at least for a non-coder like me…), I’d like to revise the initial PDF to include the results of reverse image searches for each image…
Michael Huntington is an American UFO researcher. Among other things, he posts a lot of images on on Facebook and on Twitter.
The Facebook collections are of particular interest to me because they are sorted into “albums”. Albums posted by UFO researchers on Facebook provide one means of easily obtaining relatively large sets of images already sorted into particular topics.
All the photos in a Facebook albums can be downloaded using tools such as the Chrome extension “Album Downloader for Facebook”. (Using such extensions can, however, be a bit fiddly. I had to run the tool about 30 times to eventually download 90% of the images, with Facebook twice suspending my access for a few minutes. This resulted in numerous duplicates of some files, which I eventually eliminated by searching for any files with brackets – using ~="*(*)*" – and then deleting them).
As part of a small test/demonstration, I've created a folder on the AFU’s website containing the photos from one of Michael Huntington's Facebook albums ("Clandestine Airspace"), with his kind permission. That album includes over 2,000 images – most of which are, I think, pretty cool.
Michael Huntington has explained the following to me in relation to his "Clandestine Airspace" album on Facebook:
"This album is a personal Facebook repository of images of strange aircraft, unusual aviation/aerospace concepts/developments, unique dirigibles and balloons, cutting-edge X-planes and other interesting items that may have an associative connection to the UFO Mystery. These have been found from all across the internet. It is shared with researchers with the intent of familiarizing them with some of the strange things that we may have put into our skies. I believe that it is beneficial for all UFO researchers/investigators to be familiar with aviation history, aircraft and other man-made things seen in the air."
For example:
Michael Huntington's existing Facebook Album is better for simple browsing of that collection than the folder I’ve created, but the online folder of individual jpg images is more easily downloadable ... and potentially allows for a bit of fun - outlined below.
Firstly, and most simply, I've used the downloaded images to create a large PDF which incorporates all the relevant images uploaded so far and rendered it searchable for any text used in the images themselves (e.g. "drone" or "Russian"). I turned the collection of images into single PDFs using Adobe Acrobat and then used PDFSam Basic (a free piece of software) to join the images together into a single PDF (ticking an option to create one bookmarks for each file merged into the new PDF). This means that each page of the PDF has a bookmark indicating the file name of the relevant image - just click on the option to display bookmarks in your preferred PDF viewer.
Secondly (and this is the bit with more potential, but not entirely straightforward – at least for a non-coder like me…), I’d like to revise the initial PDF to include the results of reverse image searches for each image…
edit on 24-2-2022 by IsaacKoi because: (no reason given)
SECTION C : SOCIAL MEDIA AND IMAGE DATA
Unfortunately, downloading images from Facebook (and most other modern social media platforms) strips the images of their filenames and any accompanying description. The downloaded files have rather uninformative filenames (if the downloading tool is set to retain their original Facebook filenames), such as:
“23915692_10214852826739940_1511316749643525652_n.jpg”
However, I found that it is possible to reverse engineer the Facebook URL for each photo in this album.
Each photo in the album has a URL such as facebook.com/photo/?fbid=10214852826739940&set=a.10214798590424066 - (e.g. CLICK HERE)
The second number in the URL (i.e. the bit that states &set=a.10214798590424066 in the above example) does not change and appears to relate to the album.
The first number in the URL (i.e. the bit that states ?fbid=10214852826739940 in the above example) does change. That number appears to identity a particular photo within the album. That number is included in the filename as the second number.
I did consider creating a list of URLs (by extracting the second number in each filename and then using the above details of a URL prefix and suffix) and then using code I found online for taking screenshots of each URL in that list, so that I could have snapshots of the Facebook post that included the relevant image. However:
(1) Most of the relevant Facebook posts only included the image, and generally did not include any description or discussion of the relevant image. So, saving these pages would in most (but not all) cases be a bit pointless.
(2) The code I used (see Section E below) generally worked well to take screenshots of a list of URLs, but on Facebook just resulted in screenshots of a request to accept cookies.
(3) When looking into resolving the second point above, I found that Facebook prohibits scraping and that attempting to use automated means to screenshot pages (such as passing my id and password into the relevant code and then batch accessing pages) could result in a permanent ban from Facebook. Eek.
Thinking about it a bit more, I concluded that it would actually be more productive (not to mention avoiding risking a ban from Facebook) if, instead of taking screenshots of the post that accompanied each photo, I instead sought to take screenshots of the results of a reverse image search on each of the images in the collection (and, potentially, in many other collections of UFO/IFO images).
Unfortunately, downloading images from Facebook (and most other modern social media platforms) strips the images of their filenames and any accompanying description. The downloaded files have rather uninformative filenames (if the downloading tool is set to retain their original Facebook filenames), such as:
“23915692_10214852826739940_1511316749643525652_n.jpg”
However, I found that it is possible to reverse engineer the Facebook URL for each photo in this album.
Each photo in the album has a URL such as facebook.com/photo/?fbid=10214852826739940&set=a.10214798590424066 - (e.g. CLICK HERE)
The second number in the URL (i.e. the bit that states &set=a.10214798590424066 in the above example) does not change and appears to relate to the album.
The first number in the URL (i.e. the bit that states ?fbid=10214852826739940 in the above example) does change. That number appears to identity a particular photo within the album. That number is included in the filename as the second number.
I did consider creating a list of URLs (by extracting the second number in each filename and then using the above details of a URL prefix and suffix) and then using code I found online for taking screenshots of each URL in that list, so that I could have snapshots of the Facebook post that included the relevant image. However:
(1) Most of the relevant Facebook posts only included the image, and generally did not include any description or discussion of the relevant image. So, saving these pages would in most (but not all) cases be a bit pointless.
(2) The code I used (see Section E below) generally worked well to take screenshots of a list of URLs, but on Facebook just resulted in screenshots of a request to accept cookies.
(3) When looking into resolving the second point above, I found that Facebook prohibits scraping and that attempting to use automated means to screenshot pages (such as passing my id and password into the relevant code and then batch accessing pages) could result in a permanent ban from Facebook. Eek.
Thinking about it a bit more, I concluded that it would actually be more productive (not to mention avoiding risking a ban from Facebook) if, instead of taking screenshots of the post that accompanied each photo, I instead sought to take screenshots of the results of a reverse image search on each of the images in the collection (and, potentially, in many other collections of UFO/IFO images).
edit on 24-2-2022 by IsaacKoi because: (no reason given)
SECTION D : REVERSE IMAGE SEARCHES AND CODING
As many of you will know (and as I’ve been promoting online for at least the last decade), it is easy to do a reverse image search - if you have software such as Google Chrome installed – by right clicking on the image and selecting, say, “Search image with Google Lens”.

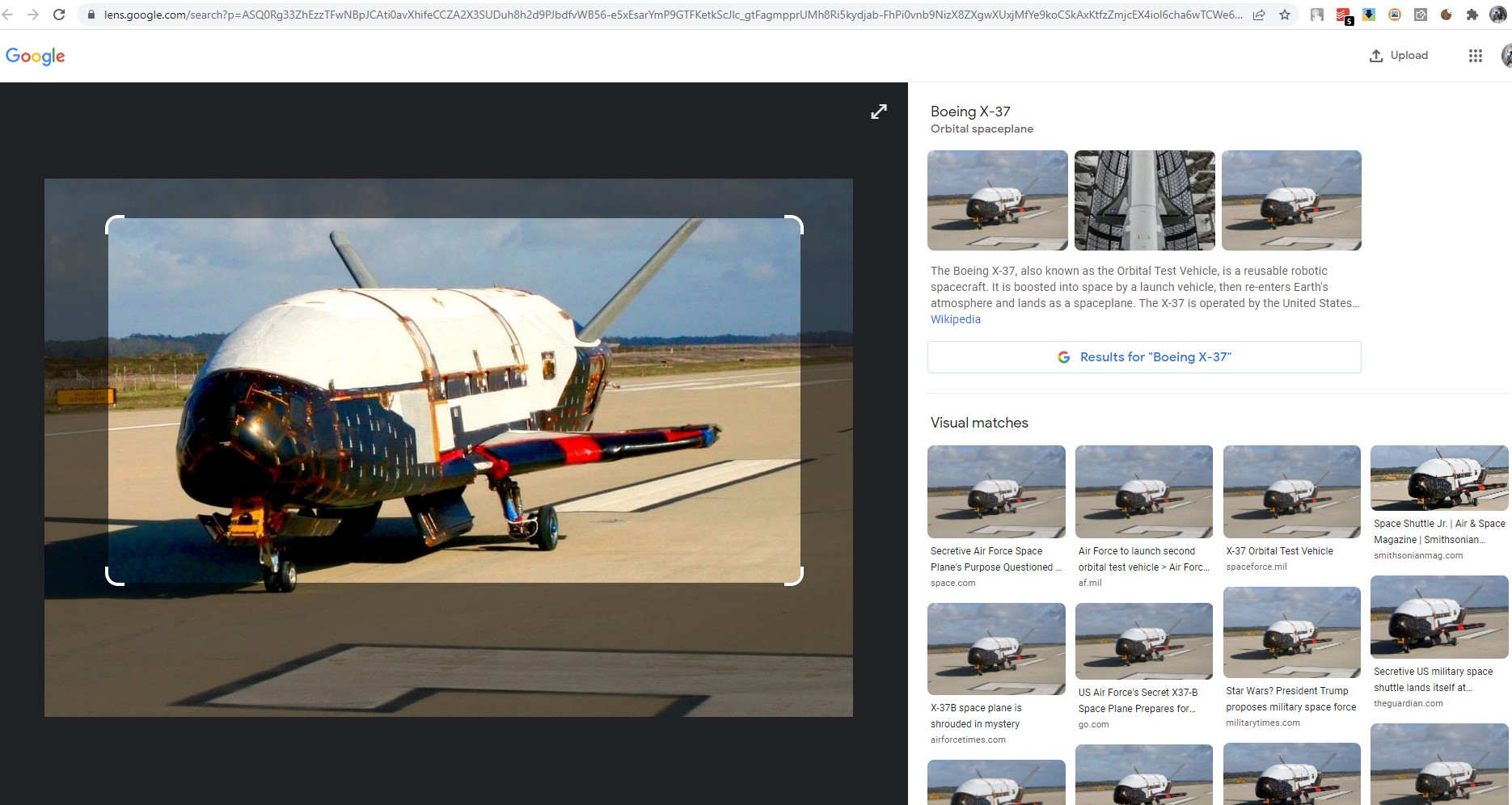
That’s fine for individual images, but what happens when you’d like to review the results of reverse image searches for hundreds or thousands of images? Doing this manually would be, well, a pain in the backside.
I, like most people involved in ufology, have limited time for this hobby so I’d like to make the process a bit more efficient by having code do the time consuming bits and generate screenshots (or PDFs) of the results of the reverse image searches on each image.
Fortunately, there are already tools that enable online reverse image searches of images stored on your computer - mainly (but not universally) by adding an option to the “context menu” that appears when you right click on an image file in Windows Explorer and – when selected – opens a browser to a page of reverse image search results.

In particular, I have installed on my Windows 10 computer:
(1) “Google Image Shell” – See a guide on the “Groovy Post” website, with links to install this tool – including to the github.com..." target="_blank" class="postlink" rel="nofollow">relevant Github repository for the exe file and source code.
(2) “SmartImage” - a reverse image search tool for Windows that can run multiple searches. See the relevant Github repository for the code and instructions.
The former software, i.e. Google Image Shell, is easier to install and use from the right-click context menu but the latter software, i.e. SmartImage, appears to be more customisable and powerful.
It is slightly more involved to install SmartImage (e.g. needing the user to also find and install .NET 6, which was a first for me anyway…) and set up the options to be used (e.g. to search using Google’s Reverse Image Search or some other search engine). The few steps involved are set out in simple installation instructions, with several screenshots of the setup process, in an article on the ilovefreesoftware website.
SmartImage looks rather promising in the current context because it can be used in various ways in addition to via the right-click context menu. Notably, it can be used via the Command Line. The instructions in the Github repository in relation to SmartImage and the Command Line options include the following examples:
(1) smartimage -se All -pe SauceNao 'https://litter.catbox.moe/x8jfkj.jpg'
Runs a search of litter.catbox.moe... with All search engines, and SauceNao as a priority engine.
(2) smartimage 'C:UsersDownloadsimage.jpg'
Runs a search of C:UsersDownloadsimage.jpg with configuration from the config file.
So, I’m hoping that SmartImage could be incorporated into a batch process relatively easily…
As many of you will know (and as I’ve been promoting online for at least the last decade), it is easy to do a reverse image search - if you have software such as Google Chrome installed – by right clicking on the image and selecting, say, “Search image with Google Lens”.
That’s fine for individual images, but what happens when you’d like to review the results of reverse image searches for hundreds or thousands of images? Doing this manually would be, well, a pain in the backside.
I, like most people involved in ufology, have limited time for this hobby so I’d like to make the process a bit more efficient by having code do the time consuming bits and generate screenshots (or PDFs) of the results of the reverse image searches on each image.
Fortunately, there are already tools that enable online reverse image searches of images stored on your computer - mainly (but not universally) by adding an option to the “context menu” that appears when you right click on an image file in Windows Explorer and – when selected – opens a browser to a page of reverse image search results.
In particular, I have installed on my Windows 10 computer:
(1) “Google Image Shell” – See a guide on the “Groovy Post” website, with links to install this tool – including to the github.com..." target="_blank" class="postlink" rel="nofollow">relevant Github repository for the exe file and source code.
(2) “SmartImage” - a reverse image search tool for Windows that can run multiple searches. See the relevant Github repository for the code and instructions.
The former software, i.e. Google Image Shell, is easier to install and use from the right-click context menu but the latter software, i.e. SmartImage, appears to be more customisable and powerful.
It is slightly more involved to install SmartImage (e.g. needing the user to also find and install .NET 6, which was a first for me anyway…) and set up the options to be used (e.g. to search using Google’s Reverse Image Search or some other search engine). The few steps involved are set out in simple installation instructions, with several screenshots of the setup process, in an article on the ilovefreesoftware website.
SmartImage looks rather promising in the current context because it can be used in various ways in addition to via the right-click context menu. Notably, it can be used via the Command Line. The instructions in the Github repository in relation to SmartImage and the Command Line options include the following examples:
(1) smartimage -se All -pe SauceNao 'https://litter.catbox.moe/x8jfkj.jpg'
Runs a search of litter.catbox.moe... with All search engines, and SauceNao as a priority engine.
(2) smartimage 'C:UsersDownloadsimage.jpg'
Runs a search of C:UsersDownloadsimage.jpg with configuration from the config file.
So, I’m hoping that SmartImage could be incorporated into a batch process relatively easily…
edit on 24-2-2022 by IsaacKoi because: (no reason given)
SECTION E : CODE TO CREATE SCREENSHOTS OF A LIST OF URL
The other part of the process that I’d like to operate is to take a screenshot of the results of each reverse image search (whether as jpg image files or pdfs).
There are various sets of code available which allow lists of URLs to be screenshotted. Perhaps the above code for reverse image searches and be used to generate a list of URLs (or more directly combined with batch methods of screenshots various URLs)?
I’ve already used one set of code to generate screenshots in bulk from multiple URLs (and there are many variations of such code online).
The particular code I have used (mainly because it was accompanied by detailed installation and operation instructions, with screenshots) is code in Python using Selenium on the Ilovefreesoftware website. This involves installing Chromedriver and Python and importing Selenium. (I would not have understood the previous sentence a few days ago, so was rather pleased with myself for being able to do this…).
The code linked to on the ilovefreesoftware page is in a related Github repository.
This code runs through list of URLs (URLs stored in a text files on one of my harddrives) and saves screenshots of the webpage at each of those URLs in a folder on that same drive
I'll paste the code below for ease of discussion:
I’m hoping that this code can be adapted to use (or combined with in another way) the SmartImage CLI commands referred to in SECTION D above.
The other part of the process that I’d like to operate is to take a screenshot of the results of each reverse image search (whether as jpg image files or pdfs).
There are various sets of code available which allow lists of URLs to be screenshotted. Perhaps the above code for reverse image searches and be used to generate a list of URLs (or more directly combined with batch methods of screenshots various URLs)?
I’ve already used one set of code to generate screenshots in bulk from multiple URLs (and there are many variations of such code online).
The particular code I have used (mainly because it was accompanied by detailed installation and operation instructions, with screenshots) is code in Python using Selenium on the Ilovefreesoftware website. This involves installing Chromedriver and Python and importing Selenium. (I would not have understood the previous sentence a few days ago, so was rather pleased with myself for being able to do this…).
The code linked to on the ilovefreesoftware page is in a related Github repository.
This code runs through list of URLs (URLs stored in a text files on one of my harddrives) and saves screenshots of the webpage at each of those URLs in a folder on that same drive
I'll paste the code below for ease of discussion:
from selenium import webdriver
from selenium.common.exceptions import WebDriverException
from tqdm import tqdm
import time
lines = []
Links_File =
r'E:url screenshotsLinks.txt'
OP_DIR = r'E:url screenshotsdownloads'
i = 1
S = lambda X: driver.execute_script('return document.body.parentNode.scroll'+X)
with open(Links_File, "r") as f:
lines = f.readlines()
lines = [line.rstrip() for line in lines]
options = webdriver.ChromeOptions()
options.less = True
options.add_argument('--log-level=3')
driver = webdriver.Chrome(options=options)
driver.execute_cdp_cmd('Network.setUserAgentOverride', ["userAgent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'])
print(driver.execute_script("return navigator.userAgent;"))
for link in tqdm(lines, ncols=65):
try:
driver.get(link)
time.sleep(5)
driver.set_window_size(S('Width'),S('Height')) # May need manual adjustment
driver.find_element_by_tag_name('body').screenshot(f'[OP_DIR][i].png')
i = i + 1
except WebDriverException:
print(link)
continue
driver.quit()
I’m hoping that this code can be adapted to use (or combined with in another way) the SmartImage CLI commands referred to in SECTION D above.
SECTION F : COMBINING THE ABOVE - CREATING SCREENSHOTS OF RESULTS?
So, over to those with a bit of coding experience…
(In the meantime, I’ll try to learn a bit more about Selenium!).
So, over to those with a bit of coding experience…
(In the meantime, I’ll try to learn a bit more about Selenium!).
How will this code be utilized after it's creation?
Just want to confirm that there will be no commercial usage.
Also, it looks like you've done most of the work already. O.o
SmartImage will probably alleviate 90% of the workload for anyone trying this challenge out. (At a glance.)
Just want to confirm that there will be no commercial usage.
Also, it looks like you've done most of the work already. O.o
SmartImage will probably alleviate 90% of the workload for anyone trying this challenge out. (At a glance.)
originally posted by: Archivalist
How will this code be utilized after it's creation?
Just want to confirm that there will be no commercial usage.
Personally, I've already created some sets of archives of UFO / IFO image (freely available online, without charge - as with all the other UFO material I've uploaded over the last decade or so...) and would like to add after each image a screenshot of the results of a reverse image search, then combine both sets of images into a revised searchable PDF of the type given in my post above (so that after each image you can glance at Google reverse image search results to see if they identify the image and/or give relevant keywords/information).
In terms of my track record of making material freely available online, rather than seeking to make commercial use of material, you can have a glance at my previous posts on ATS or on my blog. I didn't like to give a link to my blog above, but since you've raised that point you may want to have a glance at it. Basically, I've made over 400 sets of UFO magazines/newsletters from around the world freely available online after getting relevant permissions.
At the risk of over-kill, but to hopefully provide some further reassurance that I'm not out to get someone to do free work for a commercial project, I'll quote it a statement that I drafted a while ago and a list the relevant endorsements of it: Dr Kit Green (formerly of the CIA), Dr Hal Puthoff (of TTSA), Dr Eric Davis, Dr Bruce Maccabee (formerly of the US Navy), Dr Danny Ammon (of Germany's GEP), Rev Dr Ray Boeche, Dr Irena Scott, Dr Chris Cogswell, Jim Semivan (formerly of the CIA), Jenny Randles, Colonel Charles Halt (formerly of the US Air Force), Lieutenant Colonel Kevin D Randle (formerly of the US Army), Nick Pope (formerly of the UK Ministry of Defence), Dr David Clarke, Dr Chris French, Dr Gilles Fernandez, James Oberg (formerly of NASA), Robert Sheaffer, Tim Printy, Lance Moody, Curt Collins, Wendy M. Grossman (founder of "The Skeptic"), Jan Aldrich, Barry Greenwood, Edoardo Russo (of Italy's CISU), Frank Warren, Chris Rutkowski, Christopher O'Brien, Richard Doty (formerly of the US Air Force OSI), Dr Mark Rodeghier (of CUFOS), John Schuessler (of MUFON), Tony Eccles (of BUFORA), Mark Allin (co-owner of the AboveTopSecret website), Rick Hilberg, Paul Dean, Keith Basterfield, Jacques Scornaux (of France's SCEAU-Archives OVNI), Mikhail Gershtein (of Russia) and Robbie Williams (English pop star).
[BEGIN QUOTE OF EXPERT INPUT STATEMENT]
"We consider that obtaining input from disinterested experts on specific points regarding reports of 'UFOs' is likely to contribute to the study of relevant physical, historical, psychological and sociological issues. If you are able to help provide such input, we would appreciate you doing so".
[END QUOTE OF EXPERT INPUT STATEMENT]
I'd envisage that anyone else could use the code as well for any purpose, whether inside ufology or outside.
Also, it looks like you've done most of the work already. O.o
Well, I hope so - but putting the various pieces together will require that I learn more Python/Selenium than I'd prefer to do. I'm hoping that someone with a bit of experience could write a few lines of code with sufficient precision that the various bits work together...
edit on 24-2-2022 by IsaacKoi because: (no reason given)
originally posted by: alphabetaone
You want to reverse search images then.....
You want a snapshot of the reverse image results?
Is that about it?
Yes.
I have highlighted above code that will do each element as part of a batch process, but want them to work together on a batch basis (to add results of reverse image searches to several collections of hundreds/thousands of UFO/IFO photos).
edit on 26-3-2022 by IsaacKoi because: (no reason
given)
a reply to: IsaacKoi
Isaac, give me a few days to theorize on this, and do some quick and dirty prototyping. I understand you're likely comfortable with certain utilities as they are, however my personal posture is, if i CAN build a single entity to encapsulate a desired function, then i will try.
So, if you're not averse to hanging in there, ill see if i can design something that accomplishes what you would like, in a single automated fashion.
For ease of use and storage considerations and simple indexing, i tend to store images in SQL server, but im curious how you store all the images you deal with? Do you house them locally on a machine? Or do you merely use links (URL's) as a means for denoting which images you intend on reverse searching?
Isaac, give me a few days to theorize on this, and do some quick and dirty prototyping. I understand you're likely comfortable with certain utilities as they are, however my personal posture is, if i CAN build a single entity to encapsulate a desired function, then i will try.
So, if you're not averse to hanging in there, ill see if i can design something that accomplishes what you would like, in a single automated fashion.
For ease of use and storage considerations and simple indexing, i tend to store images in SQL server, but im curious how you store all the images you deal with? Do you house them locally on a machine? Or do you merely use links (URL's) as a means for denoting which images you intend on reverse searching?
edit on 26-3-2022 by alphabetaone because: (no reason given)
Isaac, small update, i threw together a very crude prototype, and made a video so that you could see the process as I think i understand it to be.
Before i started adding bells and whistles and such though, i just wanted to make sure I understood what your process actually is.
So let me explain what you'll see in the video:
A Windows for, that contains text and button controls, a web browser control for IE 11, and a Web viewer control for Microsoft Edge. I need to use 2 different paths for a variety of reasons.
There is a Website navigation button - What that does is navigate to (what i believe) a site that would contain posts with various images. In the adjacent text field would go this website address.
Once the page is loaded that contains the posts with images associated with them, I have another button on the form that then populates a combo box dropdown list with all of the links to URL's associated with the images found on that page.
Once that dropdown box is populated, i can select any of those URLs and perform a Reverse Lookup on any one particular image (in my case i use google reverse image).
After the reverse search, Then i simply press the Snapshot button to create a .JPG image of the reverse lookup results which can be stored (obviously) in a variety of ways including SQL server.
Here is the video showing me doing the manual process through my prototype:
Just shoot me a response or a U2U on whether or not I actually have the process straight. I decided to use this Thread here as an example so its easily referenced.
So let me explain what you'll see in the video:
A Windows for, that contains text and button controls, a web browser control for IE 11, and a Web viewer control for Microsoft Edge. I need to use 2 different paths for a variety of reasons.
There is a Website navigation button - What that does is navigate to (what i believe) a site that would contain posts with various images. In the adjacent text field would go this website address.
Once the page is loaded that contains the posts with images associated with them, I have another button on the form that then populates a combo box dropdown list with all of the links to URL's associated with the images found on that page.
Once that dropdown box is populated, i can select any of those URLs and perform a Reverse Lookup on any one particular image (in my case i use google reverse image).
After the reverse search, Then i simply press the Snapshot button to create a .JPG image of the reverse lookup results which can be stored (obviously) in a variety of ways including SQL server.
Here is the video showing me doing the manual process through my prototype:
Just shoot me a response or a U2U on whether or not I actually have the process straight. I decided to use this Thread here as an example so its easily referenced.
edit on 26-3-2022 by alphabetaone because: (no reason given)
originally posted by: alphabetaone
Isaac, small update, i threw together a very crude prototype, and made a video so that you could see the process as I think i understand it to be. Before i started adding bells and whistles and such though, i just wanted to make sure I understood what your process actually is.
Thanks. The process that I'd like to follow is a bit different.
Basically, I have lots of images stored on my hard drive(s). This thread gave the example of a couple of thousand images obtained from a particular Facebook album, but the sources vary (some online, some offline).
What I'd like to do (ideally as a fully automated batch process, without any human intervention for each image, due to the number of images) is to run through all the images in a folder, doing a reverse image search for each image and then storing the results of the reverse image search (whether as a screenshot or otherwise) after each image file in that folder.
So, I'd like to end up with a folder (or eventually a collection of folders) containing images from various sources with the results of a reverse image search stored with each image (possibly to be combined in a PDF for each folder, so that anyone can just scroll through the images followed by the results of the reverse image searches).
At the moment, I have a folders full of images - some of which are numbered and some of which have names (e.g. "Photo1.jpg"). I'd like the results of the reverse image searches saved with the same name with a suffix (e.g. "Photo1 - reverse image search results.jpg").
The tools (which I think are both open source) I mentioned above:
(1) Allow for reverse image searches of files, including using a command line interface set of commands (so this should presumably deal with cyclying through a folder full of images), and
(2) Automated taking screenshots.
Getting the two sets of code to work together may only require a few lines of code - I just don't know. Or a single combined program could presumably make use of some or all of the open source code from those two projects.
edit on 28-3-2022 by IsaacKoi because: (no reason given)
a reply to: IsaacKoi
The user's requirements are not clear, but this is a normal situation in sw development.
Now, let me tell you your wish list is doable, and not complex at all. At least in Lisp: it takes lees than 30 lines of code. However, my friend, the image reverse searching relies on Google image search service, which wouldn't allow you to perform multiple search before signalling your calling application as hostile. The number of queries per minute is strongly limited by Google.
This would require a new module to change IP, say, after 20 queries, which would slow down the entire process. A different approach is just to preprocess and normalize the input images (no color (is color really important at all??), edge detection, some comforter here and there, and only then query Google reverse image service).
Tell me, is the requirement of using Python (a language for kids) a must? In J language the entire thing could be coded in less than 30 lines, including a routine to educate input images (decreasing depth level, performing edge detection, and so on).
The user's requirements are not clear, but this is a normal situation in sw development.
Now, let me tell you your wish list is doable, and not complex at all. At least in Lisp: it takes lees than 30 lines of code. However, my friend, the image reverse searching relies on Google image search service, which wouldn't allow you to perform multiple search before signalling your calling application as hostile. The number of queries per minute is strongly limited by Google.
This would require a new module to change IP, say, after 20 queries, which would slow down the entire process. A different approach is just to preprocess and normalize the input images (no color (is color really important at all??), edge detection, some comforter here and there, and only then query Google reverse image service).
Tell me, is the requirement of using Python (a language for kids) a must? In J language the entire thing could be coded in less than 30 lines, including a routine to educate input images (decreasing depth level, performing edge detection, and so on).
originally posted by: Direne
Now, let me tell you your wish list is doable, and not complex at all.
Thanks for the good news - and your other comments.
However, my friend, the image reverse searching relies on Google image search service, which wouldn't allow you to perform multiple search before signalling your calling application as hostile. The number of queries per minute is strongly limited by Google.
Mmm. As long as the process is automated, I could leave it running slowly in the background for days/weeks - so I can live with a few queries per minute.
This would require a new module to change IP, say, after 20 queries, which would slow down the entire process.
If it's just a matter of slowing things down a bit, that's okay
A different approach is just to preprocess and normalize the input images (no color (is color really important at all??), edge detection, some comforter here and there, and only then query Google reverse image service).
You just lost me on how this would work or avoid the problem you mentioned above - but as long as it works then it's fine with me.
Tell me, is the requirement of using Python (a language for kids) a must?
Not at all.
It just so happens that (in the context of helping someone else) I've learnt enough Python that I can just about see how this could be done using Python and I would probably be able to adjust any Python code solution to do similar tasks in the future. So, Python is slightly preferable but certainly not a must.
a reply to: Direne
Can i be honest? My perception is that, yes, you can use out-of-process execution chains and the like to affect the merging of the two processes (unless they both have hooks for using them in other apps), however, (and Isaac, correct me if im wrong about this) I have this impression that the enduser would need something a bit more scalable - hence my back and forth on the process.
But if you know a solution that is far better, im all for it! I will bow out for now, and simply keep an eye on how it evolves from your back and forth so i can learn something!
Can i be honest? My perception is that, yes, you can use out-of-process execution chains and the like to affect the merging of the two processes (unless they both have hooks for using them in other apps), however, (and Isaac, correct me if im wrong about this) I have this impression that the enduser would need something a bit more scalable - hence my back and forth on the process.
But if you know a solution that is far better, im all for it! I will bow out for now, and simply keep an eye on how it evolves from your back and forth so i can learn something!
a reply to: IsaacKoi
I get you!
I know you want to do it all in batch, i only wanted to see if my perception of the non-automated process was accurate.
Having local images on your machine actually makes coding easier, not tougher. I had gotten the impression you were trying to first acquire the images, reverse search them, then take a snapshot of the search results. But knowing you instead house the images yourself makes it all the more simplistic, not having to deal with an HTML IO stream.
Creating folders dynamically is easy in almost any coding environment, so no sweat there.
But like i said in my above post, i will take a back seat and just watch to see what evolves with Direne.
I get you!
I know you want to do it all in batch, i only wanted to see if my perception of the non-automated process was accurate.
Having local images on your machine actually makes coding easier, not tougher. I had gotten the impression you were trying to first acquire the images, reverse search them, then take a snapshot of the search results. But knowing you instead house the images yourself makes it all the more simplistic, not having to deal with an HTML IO stream.
Creating folders dynamically is easy in almost any coding environment, so no sweat there.
But like i said in my above post, i will take a back seat and just watch to see what evolves with Direne.
originally posted by: Direne
a reply to: IsaacKoi
Tell me, is the requirement of using Python (a language for kids) a must? In J language the entire thing could be coded in less than 30 lines, including a routine to educate input images (decreasing depth level, performing edge detection, and so on).
This is a little patronising. Writing scripts in a popular and well documented language such as Python ensures good readability and compatibility for more people.
a reply to: Pretzelcoatl
I knew there would be trouble... Yes: any language would do the job.
a reply to: IsaacKoi
I've sent a PM to you with a potential solution.
I knew there would be trouble... Yes: any language would do the job.
a reply to: IsaacKoi
I've sent a PM to you with a potential solution.
originally posted by: Direne
a reply to: Pretzelcoatl
I knew there would be trouble... Yes: any language would do the job.
Lol, apologies for the predictable dev response.
I have used python/selenium and a similar C# library for testing/scraping webpages in the past and I've never been much of a fan, but without the money for bulk API requests I guess it's the next best thing.
new topics
-
Thank you dear friends
Short Stories: 3 hours ago -
An Implausible New Electoral Process?
Political Ideology: 9 hours ago -
A Couple Of Great Movies Ive Watched Today
General Chit Chat: 9 hours ago -
WHY is DOJ Not Turning Over the AUDIO of JOE BIDENs Sworn Testimony to Prosecutor Robert Hur.
Above Politics: 9 hours ago -
Boeing 737 Max whistleblower Joshua Dean, 45, dead after sudden illness
Whistle Blowers and Leaked Documents: 10 hours ago
top topics
-
Bigger than Covid
US Political Madness: 14 hours ago, 12 flags -
WHY is DOJ Not Turning Over the AUDIO of JOE BIDENs Sworn Testimony to Prosecutor Robert Hur.
Above Politics: 9 hours ago, 11 flags -
Modern Mind Control
General Conspiracies: 17 hours ago, 7 flags -
Boeing 737 Max whistleblower Joshua Dean, 45, dead after sudden illness
Whistle Blowers and Leaked Documents: 10 hours ago, 6 flags -
A Couple Of Great Movies Ive Watched Today
General Chit Chat: 9 hours ago, 6 flags -
An Implausible New Electoral Process?
Political Ideology: 9 hours ago, 4 flags -
Thank you dear friends
Short Stories: 3 hours ago, 1 flags
active topics
-
Those Fake Death Numbers From Hamas Out Of Gaza
Middle East Issues • 131 • : Lazy88 -
WHY is DOJ Not Turning Over the AUDIO of JOE BIDENs Sworn Testimony to Prosecutor Robert Hur.
Above Politics • 16 • : VariedcodeSole -
California Must Spend 20 Billion on Power Grid Upgrades If It Wants EVs
Fragile Earth • 27 • : VariedcodeSole -
Rendlesham Forest 1980 Pt II - Will There Be An Answer?
Aliens and UFOs • 3659 • : baablacksheep1 -
Israel rejected early Hamas offer to free all civilians if IDF didn’t enter Gaza
Middle East Issues • 158 • : FlyersFan -
The Acronym Game .. Pt.3
General Chit Chat • 7785 • : bally001 -
Freaky one eye website regards emerging global talent
General Conspiracies • 31 • : cavrac1 -
The Pentagon is lying about UFOs
Aliens and UFOs • 19 • : Jukiodone -
Russia Ukraine Update Thread - part 3
World War Three • 5747 • : F2d5thCavv2 -
Bigger than Covid
US Political Madness • 32 • : visitedbythem