It looks like you're using an Ad Blocker.
Please white-list or disable AboveTopSecret.com in your ad-blocking tool.
Thank you.
Some features of ATS will be disabled while you continue to use an ad-blocker.

HTTrack wildcard help? Downloading Australian UFO documents
page: 1share:
I am currently trying to download images of UFO documents from the Australian National Archives.
I know that the images are on various sets of URLs with sequential numbers.
This is similar to the position with Canada's UFO documents, which I downloaded a while ago and wrote a thread about at:
www.abovetopsecret.com...
Unfortunately, the precise method I used for the Canadian documents doesn't work so I think I finally have to work out how to use HTTrack properly rather than the simpler software I've previosuly used.
I've managed to download one 211 page file by creating a list of URL ending with sequential numbers from 1 to 211 (using Microsoft Word to create the relevant list of sequential numbers and then pasting a list of URLs into the relevant box in HTTrack).
Obviously, this is not a very elegant solution, but I seem to have some problems with running HTTrack with a wildcard character in place of the relevant number.
I'm probably just missing a character or putting something in the wrong place.
Can anyone experienced with using wildcards in HTTrack help me?
The images for the sample file are at a URL beginning:
naa12.naa.gov.au/NAAMedia/ShowImage.asp?B=3083715&S=1
The other images for this 211 page sample file are at the same URL, but ending "S=2" to "S=211".
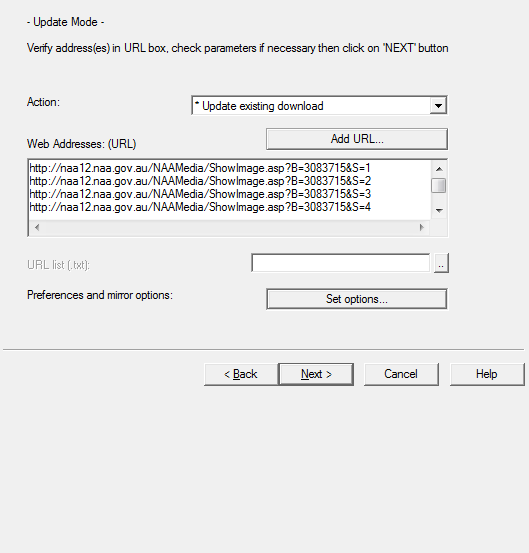
Instead of the full list of 211 (or more) URLs per file, I've tried "S=*" and "S=+*".
(From reading material on the HTTrack website, I thought the wildcard solution was simply to replace the final number with a + followed by *).
Unfortunately, these attempts to use a wildcard failed.
What am I missing??
I know that the images are on various sets of URLs with sequential numbers.
This is similar to the position with Canada's UFO documents, which I downloaded a while ago and wrote a thread about at:
www.abovetopsecret.com...
Unfortunately, the precise method I used for the Canadian documents doesn't work so I think I finally have to work out how to use HTTrack properly rather than the simpler software I've previosuly used.
I've managed to download one 211 page file by creating a list of URL ending with sequential numbers from 1 to 211 (using Microsoft Word to create the relevant list of sequential numbers and then pasting a list of URLs into the relevant box in HTTrack).
Obviously, this is not a very elegant solution, but I seem to have some problems with running HTTrack with a wildcard character in place of the relevant number.
I'm probably just missing a character or putting something in the wrong place.
Can anyone experienced with using wildcards in HTTrack help me?
The images for the sample file are at a URL beginning:
naa12.naa.gov.au/NAAMedia/ShowImage.asp?B=3083715&S=1
The other images for this 211 page sample file are at the same URL, but ending "S=2" to "S=211".
Instead of the full list of 211 (or more) URLs per file, I've tried "S=*" and "S=+*".
(From reading material on the HTTrack website, I thought the wildcard solution was simply to replace the final number with a + followed by *).
Unfortunately, these attempts to use a wildcard failed.
What am I missing??
edit on 21-3-2013 by IsaacKoi because: (no reason given)
I'm sure my failure to get the wildcard function working is something very minor, like a missing character - but I stil haven't been able to work it
out.
I've now done about a third of the relevant files - but if I'm going to post a thread on ATS about downloading this material then I'd much rather be able to post instructions that don't involve my fix of creating a list of sequential URLs rather than getting the wildcard function to work.
I've now done about a third of the relevant files - but if I'm going to post a thread on ATS about downloading this material then I'd much rather be able to post instructions that don't involve my fix of creating a list of sequential URLs rather than getting the wildcard function to work.
I dont know about HTTrack, I've only used it a couple times to copy entire web sites.
But if your on linux, or have access to a linux box, this can be done very easily with only a few lines of bash and wget magic.
Here's something I just threw together:
But if your on linux, or have access to a linux box, this can be done very easily with only a few lines of bash and wget magic.
Here's something I just threw together:
#!/bin/bash
CNT=0
URL="http://naa12.naa.gov.au/NAAMedia/ShowImage.asp?B=3083715&S="
while [ $CNT -lt 211 ]
do
CNT=$(( $CNT+1 ))
wget -O "image-$[CNT].jpg" $[URL]$CNT
done
Originally posted by Kr0nZ
if your on linux, or have access to a linux box, this can be done very easily with only a few lines of bash and wget magic.
Thanks, but I've never used linux. I can't say I'm keen to start now
I've now downloaded about half of the Australian files using the rather basic method of creating a list of URLs and pasting that into HTTrack, so my main objectives in still seeking an answer to this HTTrack wildcard issue are now to know how to use HTTrack more effectively in the future and being able to tell others a simple way to duplicate the downloading of the Australian files (if I can't get permission to share the searchable PDF files I'm creating).
I don't particularly want to post the rather rudimentary list method I'm using now because (while it's fairly quick to create the relevant list) there MUST be a way to do this using a wildcard function in HTTrack or other similar (relatively) user friendly software...
edit on 21-3-2013 by
IsaacKoi because: (no reason given)
I don't know if WinHTTrack is the best tool for that specific job, I think it's better for downloading pages with links, as it follows the links to
other pages and downloads them.
In cases like this I usually make a HTML page with the list of the images I want to download (I usually use Excel to create the list, as it allows us to write the first element of a sequence and then create the whole sequence with as many elements as we want) and the I use FreeDownloadManager to download all images on that page.
The resulting page is something like this.
In cases like this I usually make a HTML page with the list of the images I want to download (I usually use Excel to create the list, as it allows us to write the first element of a sequence and then create the whole sequence with as many elements as we want) and the I use FreeDownloadManager to download all images on that page.
The resulting page is something like this.
Originally posted by ArMaP
In cases like this I usually make a HTML page with the list of the images I want to download (I usually use Excel to create the list, as it allows us to write the first element of a sequence and then create the whole sequence with as many elements as we want) and the I use FreeDownloadManager to download all images on that page.
The resulting page is something like this.
That seems to be pretty similar to the method I'm currently using.
I pasted a list of numbers from 1 to 1000 in Microsoft Word with an "a" in front of each number. To create a list of URLs, I just do a quick global "search and replace", replacing each "a" with the relevant base URL. This is actually fairly quick to do. I just don't fancy posting this method in a thread about downloading the Australian documents because I'll get told, "you should have used a wildcard instead..."!
But if no-one else knows how to get the wildcard function (which does appear to exist in HTTrack, I just can't seem to get it to work in this context), then I feel like less of an idiot.
reply to post by IsaacKoi
To me, it looks like the wildcard in WinHTTrack works only for what type of link or resource it should follow/download from the pages it is looking at. As in this case the pages do not really exist, they just return an image, WinHTTrack doesn't have anything to work with.
But I may be wrong, obviously.
To me, it looks like the wildcard in WinHTTrack works only for what type of link or resource it should follow/download from the pages it is looking at. As in this case the pages do not really exist, they just return an image, WinHTTrack doesn't have anything to work with.
But I may be wrong, obviously.
Originally posted by ArMaP
To me, it looks like the wildcard in WinHTTrack works only for what type of link or resource it should follow/download from the pages it is looking at. As in this case the pages do not really exist, they just return an image, WinHTTrack doesn't have anything to work with.
Thanks for taking a look.
Mmm. Well, I'll just carry on creating a list of the relevant numbers. I've done well over half of the files. It still feels a bit silly...
edit on 22-3-2013 by IsaacKoi because: (no reason given)
Try going to this page, and log in as a guest naa12.naa.gov.au...
Then use naa12.naa.gov.au... as your starter.
This resource is a valuable aid httrack help
Then use naa12.naa.gov.au... as your starter.
This resource is a valuable aid httrack help
Originally posted by Watchfull
Try going to this page, and log in as a guest naa12.naa.gov.au...
Then use naa12.naa.gov.au... as your starter.
Hi Watchfull,
I tried logging in as a guest and then using the NAAMedia URL, but get an error message.
This resource is a valuable aid httrack help
Thanks, but I don't see any instructions there in relation to the use of wildcards beyond the instructions I mentioned in the OP (which I still haven't got working).
I've now downloaded about 75% of the files and converted them to searchable PDF documents. For my present purposes, I'll probably now just stick with the method I've been using for the last day or two.
Using Kr0nZ's idea, and knowing that most Linux useful programs have a Windows version, I went looking for a Windows version of wget and found
Wget for Windows.
So I downloaded and installed it, then converted the bash script to make it work in Windows.
I tested it on Windows 8 and it worked, in 10 minutes I had all the files on my computer.
Here's the code for the batch file:
You just need to make a .bat file with the above code and save it on the same folder as the wget.exe. In the above code it will try to download the images to a C:\tmp\images folder, but if it doesn't exist it will not create the folder or give an error, it will try to download the files to nowhere.
I hope this helps.
So I downloaded and installed it, then converted the bash script to make it work in Windows.
I tested it on Windows 8 and it worked, in 10 minutes I had all the files on my computer.
Here's the code for the batch file:
set cnt=1
set end=211
set url=http://naa12.naa.gov.au/NAAMedia/ShowImage.asp?B=3083715^&S=
:repeat
echo %cnt%
wget -O "C:\tmp\images\image-%cnt%.jpg" "%url%%cnt%"
set /a cnt=%cnt%+1
if %cnt% GTR %end% goto close
goto repeat
:close
You just need to make a .bat file with the above code and save it on the same folder as the wget.exe. In the above code it will try to download the images to a C:\tmp\images folder, but if it doesn't exist it will not create the folder or give an error, it will try to download the files to nowhere.
I hope this helps.
Originally posted by ArMaP
Using Kr0nZ's idea, and knowing that most Linux useful programs have a Windows version, I went looking for a Windows version of wget and found Wget for Windows.
Very interesting. I'll certainly try that tomorrow since it will be useful for other projects I'm planning.
I tested it on Windows 8 and it worked, in 10 minutes I had all the files on my computer.
I've been averaging about 10 to 20 minutes per file of documents (with each file varying between about 100 and 350 pages of documents), so if you've downloaded all the Australian UFO files on the National Archives website in 10 minutes then this is a vast improvement.
(Or do you mean you downloaded the single sample file mentioned in the OP in 10 minutes?)
Originally posted by IsaacKoi
(Or do you mean you downloaded the single sample file mentioned in the OP in 10 minutes?)
I downloaded the 211 files (pages) of the file (document) from your OP.
I forgot that "file" has more meanings, sorry for that.
Originally posted by ArMaP
Here's the code for the batch file:
Many thanks for the pointers and code.
I got that code running in a batch file and it's definitely a bit easier than creating the lists of URLs.
I've modified the code for the batch file (the first time I've done that in a couple of decades...) to enable it to be used for downloading all of the Australian UFO files (and, I think, probably more than that...).
The code I've used is:
@echo off
:beginning
cls
set cnt=1
set /p url= What is the base URL (i.e. before the number that changes)?
set /p end= How many pages are in the relevant file?
:downloadloop
echo %cnt%
wget64 -O "C:Downloadswgetimagesimage-%cnt%.jpg" "%url%%cnt%"
set /a cnt=%cnt%+1
if %cnt% GTR %end% goto finishquestion
goto downloadloop
:end
:finishquestion
set /p finished= Have you finished downloading (yes/no)?
If "%finished%" == "no" goto beginning
:close
I've uploaded a copy of the code, batch file and Winget64 (since I use WIndows 7 64 bit) to the same folder on Minus.com (which I plan on using in the thread I'll write, eventually, about the Australian files if I don't obtain permission from the Australian government to share the searchable PDF versions I'm creating):
www.box.com...
Mmm. I wonder if there is an easy way to have the batch file make a new sub-directory for each new sequence of URLs? I don't think it is possible to just use the mkdir and the base URL variable, since the base URL variable has various characters that can't be used in a file (with various colons, slashes etc). Not a big deal, but at the moment I have to clear out the relevant download directory after each sequence of URLs (i.e. each file of documents). This isn't a major problem and I'm quite happy with the code as is.
edit on 23-3-2013 by IsaacKoi because: (no reason
given)
For a different approach to downloading these files, see Xtraeme's post:
www.abovetopsecret.com...
I've only just seen Xtraeme's executable file and source code. If I'd seen that earlier, I may have simply adopted and adapted that approach. At the moment, I think the batch file and Wget combination is probably more easily adapted for some future problems and I'll probably stick with this approach...
www.abovetopsecret.com...
I've only just seen Xtraeme's executable file and source code. If I'd seen that earlier, I may have simply adopted and adapted that approach. At the moment, I think the batch file and Wget combination is probably more easily adapted for some future problems and I'll probably stick with this approach...
reply to post by IsaacKoi
Hey Isaac,
Wget is always preferable, but there is always the chance the website you're accessing uses robots.txt in which case you need to "customize" the exe. Nevertheless stick with the command line script if you can. The only reason I used code from the GUI reaper was because it doesn't depend on a constant increment to find the next URL. Though with the Australian National Archive since the website just uses an ASP.Net backend. It's easy enough to sniff the "next page" link by just grep'ing the html. Anyhow, thanks for letting me know about this thread all the documents you put together. More reading!
Cheers,
-Xt
Hey Isaac,
Wget is always preferable, but there is always the chance the website you're accessing uses robots.txt in which case you need to "customize" the exe. Nevertheless stick with the command line script if you can. The only reason I used code from the GUI reaper was because it doesn't depend on a constant increment to find the next URL. Though with the Australian National Archive since the website just uses an ASP.Net backend. It's easy enough to sniff the "next page" link by just grep'ing the html. Anyhow, thanks for letting me know about this thread all the documents you put together. More reading!
Cheers,
-Xt
edit on 23-3-2013 by Xtraeme because: (no reason given)
Originally posted by IsaacKoi
Mmm. I wonder if there is an easy way to have the batch file make a new sub-directory for each new sequence of URLs? I don't think it is possible to just use the mkdir and the base URL variable, since the base URL variable has various characters that can't be used in a file (with various colons, slashes etc).
You can also ask for that, along with URL, right?
It would become something like this:
@echo off
:beginning
cls
set cnt=1
set /p url= What is the base URL (i.e. before the number that changes)?
set /p end= How many pages are in the relevant file?
set /p folder= Name of the folder where you want to save the images?
md %folder%
:downloadloop
echo %cnt%
wget64 -O "%folder%\image-%cnt%.jpg" "%url%%cnt%"
set /a cnt=%cnt%+1
if %cnt% GTR %end% goto finishquestion
goto downloadloop
:end
:finishquestion
set /p finished= Have you finished downloading (yes/no)?
If "%finished%" == "no" goto beginning
:close
If the folder already exists it throws an error and continues with the download.
Not the most elegant solution, but it's the quickest.
Originally posted by ArMaP
You can also ask for that, along with URL, right?
Sure, but that's one more human input (slowing things down a bit and, more importantly, introducing another cause of human error).
As I mentioned, I don't really need a separate folder per download since I'm converting the jpegs into searchable PDFs as I go, and then deleting the jpeg from the download folder - so (for my purposes at least) it doesn't really matter that the next download goes into that folder.
But your addition will probably help other people, so I'll nick your version for use in the thread I'll get around to posting at some point about these files!
Not the most elegant solution, but it's the quickest.
Hey, I'm all in favour of quick and easy solutions - particularly when the number of files isn't huge so it isn't worth customising the code that much...
I'm almost done with the downloading now, I think (subject to finding more files).
By the way, all that really changes in the URL for each file is an element referred to by the Australian National Archives as the "Barcode". I've found a few partial lists of such "Barcodes" for the Oz UFO files. See, for example, the relevant column in a table put together by (I think) a group associated with Keith Basterfield:
www.auforn.com...
I think that all I need to post (apart from some highlights from the files, which means reading them all) is a list of the file names, with their barcode number and the number of pages in that file (with some instructions on downloading wget and the batch file from the box.com link I gave above) - assuming that the National Archives don't simply give me permission to share a folder full of the searchable PDFs.
I'll finish the downloading exercise first then email the copyright permission office at the Australian National Archives about sharing the PDFs.
edit on 23-3-2013 by IsaacKoi because: (no reason given)
If you want you could also make a python, or perl script, to do it, then it would need hardly any user input. You would just need to post a list of
barcodes on something like pastebin. Benefit of doing it this way is it would work on multiple OSes, Windows, Linux, Mac, but you would need to
install python, or perl. You could even add barcodes to the pastebin file if you find more.
Python would be best IMO.
If you want to do it that way I could throw something together for you.
Python would be best IMO.
If you want to do it that way I could throw something together for you.
edit on 23/3/13 by Kr0nZ because: (no reason given)
Originally posted by Kr0nZ
If you want you could also make a python, or perl script, to do it, then it would need hardly any user input. You would just need to post a list of barcodes on something like pastebin.
Mmm. Personally, I'm about finished downloading - but now you mention it, I could probably quite quickly adapt the code for the batch file above so the list of National Archive files (and other details, e.g. number of pages for that folder names) are built into the batch file, so all anyone (or at least anyone with 64 bit Windows, since that's the version of Wget included at box.com folder I've created at the link above) has to do is download the files in that folder and then run the batch file and it will download all the images for all the known files.
I'd prefer to share the searchable PDFs, but I'd need the permission of the National Archives (on behalf of the Australian government to agree).
If you want to do it that way I could throw something together for you.
Thanks for the generous offer, but given that I've now nearly finished downloading files and MAY be able to get permission just to share the searchable PDFs so that no-one else has to download these files directly from the National Archives website, I don't like to impose on your time (particularly when any perl or python script you put together would probably not be anything I could adapt without coming back you, whereas I can just about remember how to write batch files from my long-ago days of doing some projects with MS-DOS...).
However, anyone reading this far in this thread may have some experience with Python and AutoIt (and/or AutoHotKey and Batch scripting). If so, some help is needed to fine tune the code for a MUCH more important and bigger project relating to UFO documents. If anyone would like to help with that, send me a message or email ([email protected]) for more details.
edit on 23-3-2013 by IsaacKoi because: (no reason given)
new topics
-
Israeli Missile Strikes in Iran, Explosions in Syria + Iraq
World War Three: 6 minutes ago -
George Knapp AMA on DI
Area 51 and other Facilities: 5 hours ago -
Not Aliens but a Nazi Occult Inspired and then Science Rendered Design.
Aliens and UFOs: 5 hours ago -
Louisiana Lawmakers Seek to Limit Public Access to Government Records
Political Issues: 8 hours ago -
The Tories may be wiped out after the Election - Serves them Right
Regional Politics: 9 hours ago -
So I saw about 30 UFOs in formation last night.
Aliens and UFOs: 11 hours ago
top topics
-
BREAKING: O’Keefe Media Uncovers who is really running the White House
US Political Madness: 12 hours ago, 25 flags -
George Knapp AMA on DI
Area 51 and other Facilities: 5 hours ago, 19 flags -
Biden--My Uncle Was Eaten By Cannibals
US Political Madness: 13 hours ago, 18 flags -
"We're All Hamas" Heard at Columbia University Protests
Social Issues and Civil Unrest: 13 hours ago, 7 flags -
Louisiana Lawmakers Seek to Limit Public Access to Government Records
Political Issues: 8 hours ago, 7 flags -
Russian intelligence officer: explosions at defense factories in the USA and Wales may be sabotage
Weaponry: 17 hours ago, 6 flags -
So I saw about 30 UFOs in formation last night.
Aliens and UFOs: 11 hours ago, 5 flags -
The Tories may be wiped out after the Election - Serves them Right
Regional Politics: 9 hours ago, 3 flags -
Do we live in a simulation similar to The Matrix 1999?
ATS Skunk Works: 12 hours ago, 3 flags -
Not Aliens but a Nazi Occult Inspired and then Science Rendered Design.
Aliens and UFOs: 5 hours ago, 3 flags
active topics
-
MULTIPLE SKYMASTER MESSAGES GOING OUT
World War Three • 35 • : Zaphod58 -
Israeli Missile Strikes in Iran, Explosions in Syria + Iraq
World War Three • 0 • : FamCore -
Candidate TRUMP Now Has Crazy Judge JUAN MERCHAN After Him - The Stormy Daniels Hush-Money Case.
Political Conspiracies • 386 • : WeMustCare -
British TV Presenter Refuses To Use Guest's Preferred Pronouns
Education and Media • 61 • : nugget1 -
-@TH3WH17ERABB17- -Q- ---TIME TO SHOW THE WORLD--- -Part- --44--
Dissecting Disinformation • 535 • : cherokeetroy -
African "Newcomers" Tell NYC They Don't Like the Free Food or Shelter They've Been Given
Social Issues and Civil Unrest • 15 • : marg6043 -
Alabama Man Detonated Explosive Device Outside of the State Attorney General’s Office
Social Issues and Civil Unrest • 58 • : Unknownparadox -
BREAKING: O’Keefe Media Uncovers who is really running the White House
US Political Madness • 13 • : WeMustCare -
"We're All Hamas" Heard at Columbia University Protests
Social Issues and Civil Unrest • 127 • : marg6043 -
Two Serious Crimes Committed by President JOE BIDEN that are Easy to Impeach Him For.
US Political Madness • 16 • : WeMustCare